RAGとファインチューニングの違い|選び方を比較表で解説【2026】
一次ソース検証型AIメディア編集部 ・ 監修: 依田 尚人
目次
RAG(検索拡張生成)とファインチューニング(FT)は、どちらもLLMを自社用途に寄せる代表的な手法だが、役割はまったく違う。結論から言えば、最新情報や社内文書のように「中身が変わる事実」を扱いたいならRAG、文体・出力形式・特定タスクの安定性のように「振る舞い」を整えたいならFTを選ぶ。多くの実務では、まずRAGとプロンプトで足りるかを試し、足りない部分だけFTで補うのが現実解になる。本記事は2026年6月25日時点の各社公式情報に基づき、どちらの手法も勝たせず中立に整理する。
迷ったら「扱いたいのは最新情報か、振る舞いか」で分ける。最新情報・社内文書・頻繁な更新・計算資源が限られる場合は RAG 、専門文体・出力フォーマットの固定・特定タスクの最高精度・安定したコンテンツは ファインチューニング が起点になる。多くの場合は併用が現実解で、判断軸は「コスト・最新性・精度・運用負荷・専門性・データ更新」の6項目で比べると整理しやすい(2026-06-25時点)。
なお当社(YDAIコンサルティング AI編集部)は Claude 系ツールのヘビーユーザーであり、AIエコシステムでの開発受託も行う立場にある。そのうえで、本記事はRAG・ファインチューニングのどちらも勝たせず中立に整理する。特定ベンダーや製品を推奨せず、自社サービスへの送客は一切しない。
結論:どちらを選ぶかは「最新情報か、振る舞いか」で決まる
万能の正解は1つではなく、扱いたい対象で選ぶ。下表は「観点→RAG→ファインチューニング」を1行で結ぶ用途別早見表である。教科書的な特徴列挙ではなく、実務で迷う観点に絞って並べた。
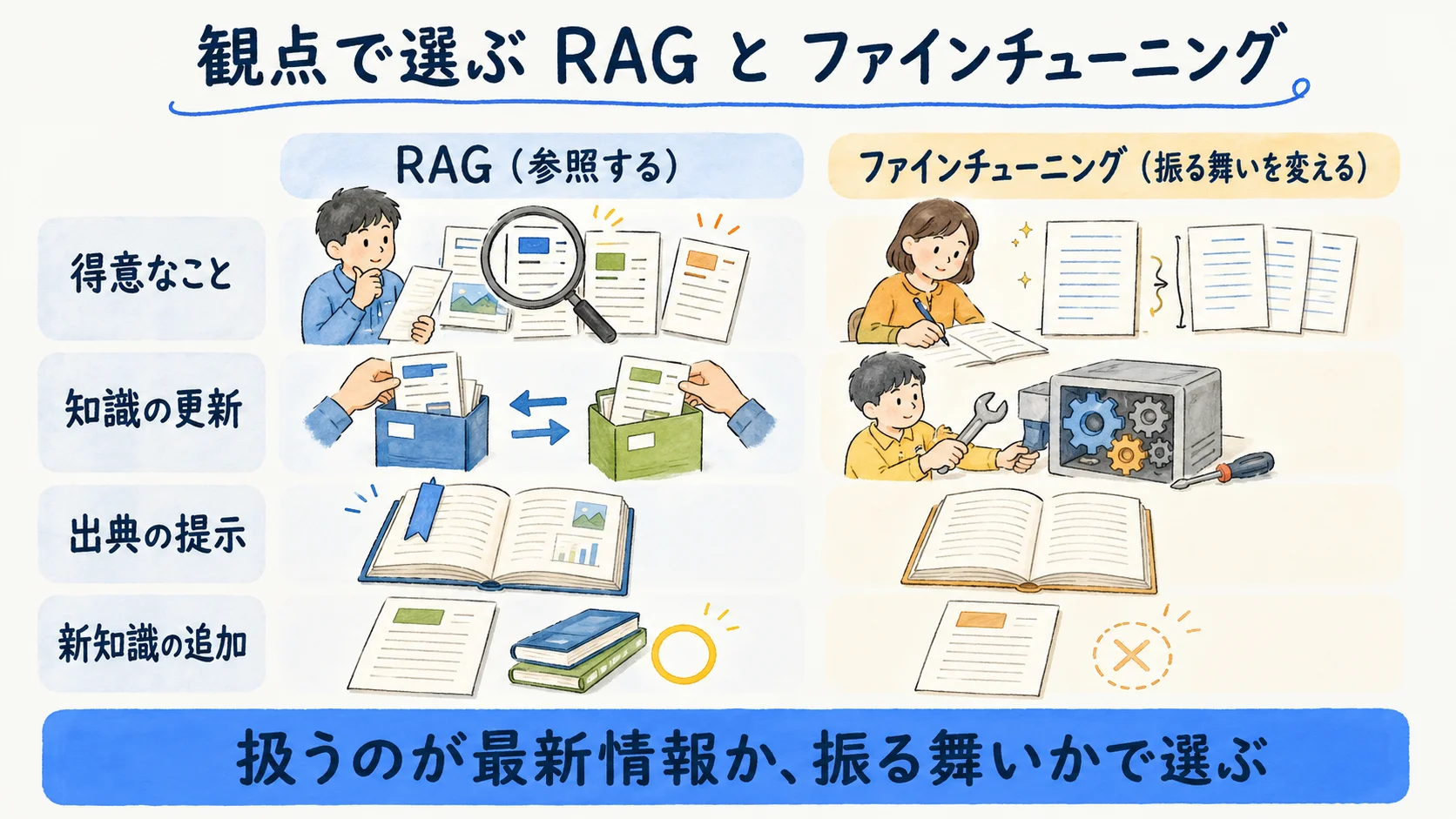
| 観点 | RAG(参照する) | ファインチューニング(振る舞いを変える) |
|---|---|---|
| 得意なこと | 最新情報・社内文書など変わる事実の反映 | 文体・出力形式・特定タスクの安定 |
| 知識の更新 | ソースを差し替えるだけで反映 | ドメイン変化時は再学習が必要 |
| 出典の提示 | 参照元を示しやすい | 出力に出典を持たせにくい |
| 向く場面 | 動的・広範・計算資源が限られる | 専門文体固定・良質な教師データがある |
| 新知識の追加 | 得意 | 不向き(振る舞いを整える用途) |
RAGはモデルを再学習せずに(without retraining the model)外部の権威ある知識ベースを参照してから回答を生成する仕組みで、最新情報・出典提示・ハルシネーション抑制が利点だ(出典: AWS「What is RAG」・2026-06-25時点)。一方ファインチューニングは事前学習済みLLMを小さな特定データセットで再学習し、学習時にモデルの重みを更新して特定タスクや文体に寄せる(出典: Microsoft Learn・2026-06-25時点)。結論は用途で割れるため、本記事は最後まで「どちらが勝ち」とは断定しない。
定義の違い:覚えさせるのがFT、参照するのがRAG
混乱の多くは、両者を同じ土俵で比べることから生じる。最小の対比で言えば、RAGは「外を参照する」、ファインチューニングは「中を作り替える」だ。RAGそのものの仕組み・できることの基礎は別途まとめる(本記事では深掘りせず最小対比に絞る)。
RAG=外部知識を参照して回答する(再学習しない)
RAGは、社内文書などをベクトル化して検索可能にし、質問に近いチャンクを取り出してLLMに渡し、それを根拠に回答を生成する。モデルの重みは変えず、参照するソースを差し替えるだけで知識を更新できる。再学習が不要なため、最新情報の反映・出典提示・ハルシネーション抑制に向く(出典: AWS「What is RAG」・2026-06-25時点)。
ファインチューニング=重みを更新して振る舞いを変える
ファインチューニングは、事前学習済みのモデルを特定タスク向けの小さなデータセットでさらに学習させ、その過程でモデルの重みを更新する。これにより分類・特定フォーマットの生成・指示追従といった「どう振る舞うか」を安定させられる。短所は、大量の良質な教師データが要る・過学習のリスク・計算コスト・ドメインが変わるたびの再学習保守・汎用性の低下(model drift)だ(出典: Microsoft Learn・2026-06-25時点)。なおRAGの原典は Lewis らの「Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks」(NeurIPS 2020・arXiv:2005.11401)で、モデル内部の知識と外部検索を結合する発想が示された(出典: arXiv:2005.11401・2026-06-25時点)。
項目別の比較表:コスト・最新性・精度・運用負荷・専門性・データ更新
早見表をもう一段深め、実務で効く6項目で並べる。金額・パーセント・レイテンシといった具体数値は変動が速く一次で確定できないため、本記事では出さず、前払い/後払い・容易/要再学習といった方向性のみで示す。
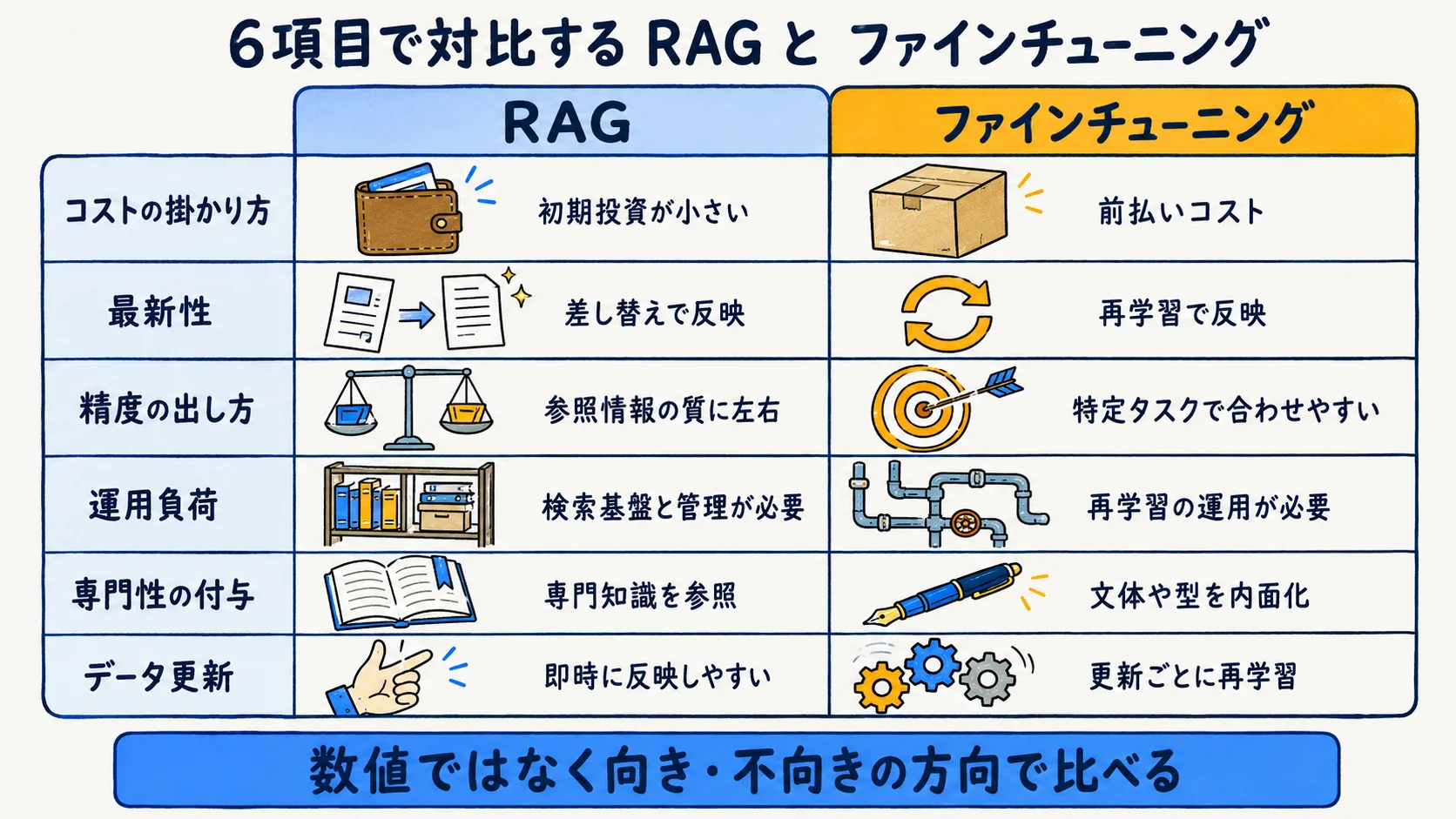
| 項目 | RAG | ファインチューニング |
|---|---|---|
| コストの掛かり方 | 初期投資が小さく後から調整しやすい | 学習に前払いコスト(教師データ整備が前提) |
| 最新性 | ソース差し替えで最新を反映 | ドメイン変化時は再学習が必要 |
| 精度の出し方 | 参照情報の質に依存 | 特定タスクで最高精度を狙える |
| 運用負荷 | 検索基盤とソース管理の保守 | 再学習パイプラインの保守 |
| 専門性の付与 | 参照先の専門文書で補強 | 文体・形式そのものを内面化 |
| データ更新 | 容易(即時反映しやすい) | 反映に再学習が要る |
RAGは初期投資が小さくソースの差し替えが容易な一方、検索ステップのぶん推論はやや遅くなる傾向がある。ファインチューニングは学習に前払いのコストがかかるが、いったん学習すれば推論レイテンシは増えにくい、という対照がある(出典: Label Your Data・補強・2026-06-25時点)。コストの具体的な試算は手法選択とは別の話題のため、金額レンジを含む見積りは「AIエージェント開発コストの考え方」へ委譲する。本記事では金額やパーセントは断定せず、変動値は公式参照・要再確認(2026-06-25時点)として扱う。
RAGが向くケース
RAGは「変わる事実を、再学習なしで反映したい」場面で効く。社内の問い合わせ対応や、更新の多い規程・マニュアルを根拠付きで答えさせたいときが典型だ。
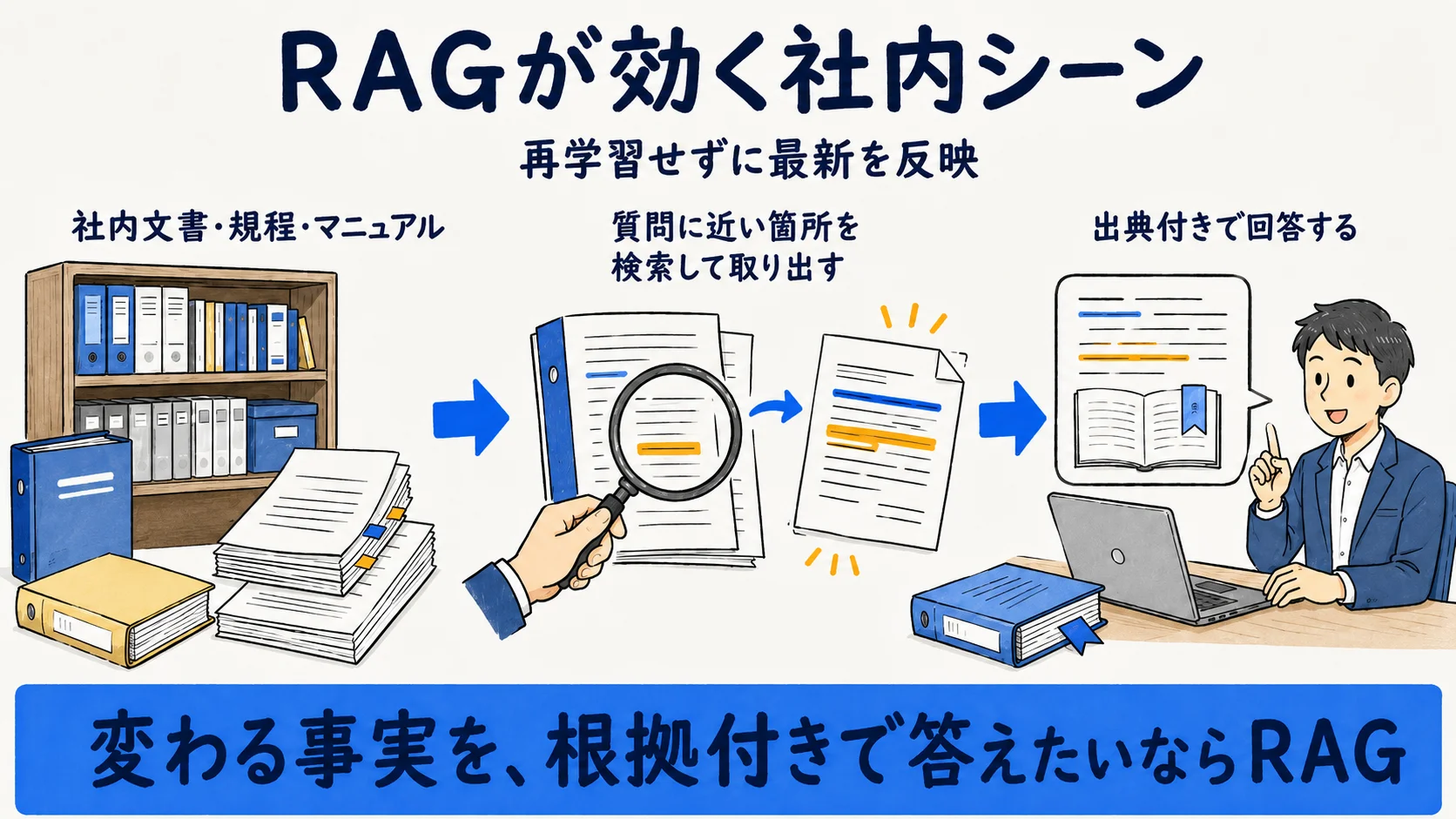
具体的には、扱うデータが動的・頻繁に変わる、最新情報が要る、対象トピックが広範、データや計算資源が限られる、といった条件のときにRAGが基本になる(出典: Microsoft Learn・2026-06-25時点)。加えて、回答に参照元を示したい(出典提示)、もっともらしい誤りを抑えたい(ハルシネーション抑制)といったニーズにも向く(出典: AWS「What is RAG」・2026-06-25時点)。社内ナレッジ検索や一次対応のように「答えの根拠を出せること」自体が価値になる用途では、RAGが第一候補になりやすい。
ファインチューニングが向くケース
ファインチューニングは「事実を増やす」のではなく「振る舞いを固める」手法だと捉えると、向き不向きがはっきりする。特定の文体・出力形式を毎回ぶれずに出したい、決まったタスクで最高精度を出したい、という場面で効く。
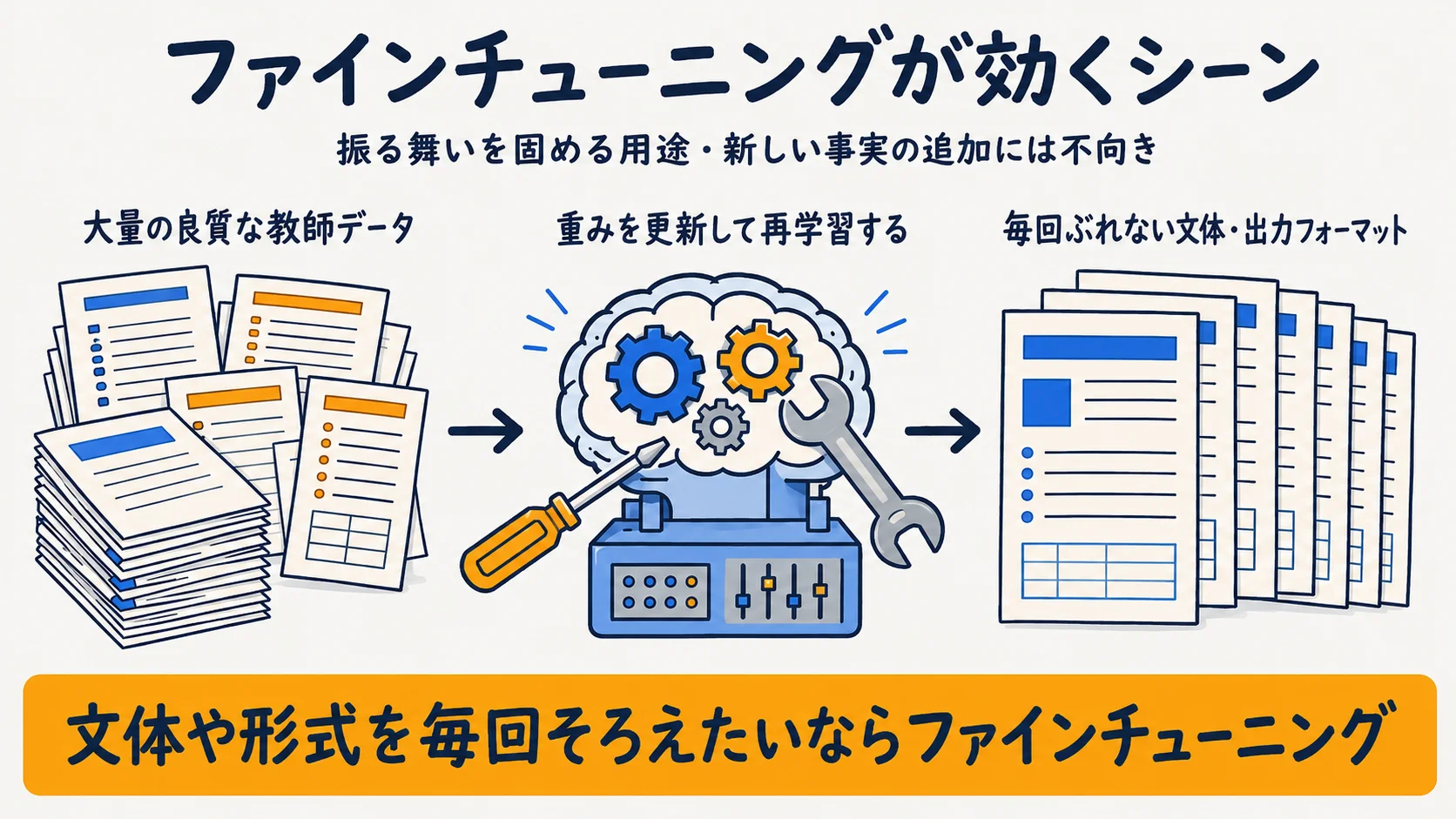
向くのは、専門的な文体やフォーマットを固定したい、特定タスクで最高精度が要る、扱うコンテンツが安定している、ベースモデルと大きく異なる独自データがある、といったケースだ。前提として、大量の良質な教師データが用意できることが条件になる(出典: Microsoft Learn・2026-06-25時点)。一方で注意したいのは、ファインチューニングは新しい事実・知識を教える用途には向かないという点だ。OpenAIは最適化の順序として「まず評価、次に効果的なプロンプト、必要ならファインチューニング」を推奨し、FTは分類・特定フォーマット生成・指示追従の改善など「どう振る舞うか」を整える用途だと位置づけている(出典: OpenAI・2026-06-25時点)。最新情報の担保はRAG側の役割と切り分けるのが定石だ。
併用パターン:形式はFTで固定し、最新の事実はRAGで載せる
RAGとファインチューニングは排他ではなく、組み合わせられる。役割分担をはっきりさせれば、両者の弱点を補い合える。
代表的なハイブリッドは、出力の形式やスタイルをファインチューニングで内面化させ、動的で最新の事実はRAGで都度参照させる構成だ。形式の一貫性はFTが、引用付きの最新性はRAGが担う。設計の順序としては、OpenAIの推奨どおり、まずプロンプトとRAGで要件を満たせるかを試し、それでも足りない振る舞いの部分だけをファインチューニングで足すと、過剰投資を避けやすい(出典: OpenAI/Microsoft Learn・2026-06-25時点)。Microsoft Learn も、ファインチューニングをタスク特化、RAGを動的・最新コンテンツの柔軟性と整理し、目的に応じて選ぶ・組み合わせる設計を示している(出典: Microsoft Learn・2026-06-25時点)。「どちらか一方」ではなく「どこをFTで固め、どこをRAGで賄うか」という分担で考えるのが実務的だ。
中小企業の現実的な判断:まずRAG、FTは条件が揃った最後の手段
ここまでの整理を、当社の現場観察と突き合わせる。YDAIコンサルティング AI編集部は16以上の事業で社内ナレッジ検索や問い合わせの一次対応を運用しており、複数業種の実務者ヒアリングも重ねてきた。そこで繰り返し見えたのは、「ファインチューニングを検討したものの、更新頻度・データ整備コスト・運用保守の負担が見合わず、結局RAG(とプロンプト調整)で足りた」という分布だ(当社AI編集部の定性観察・2026-06-25時点)。
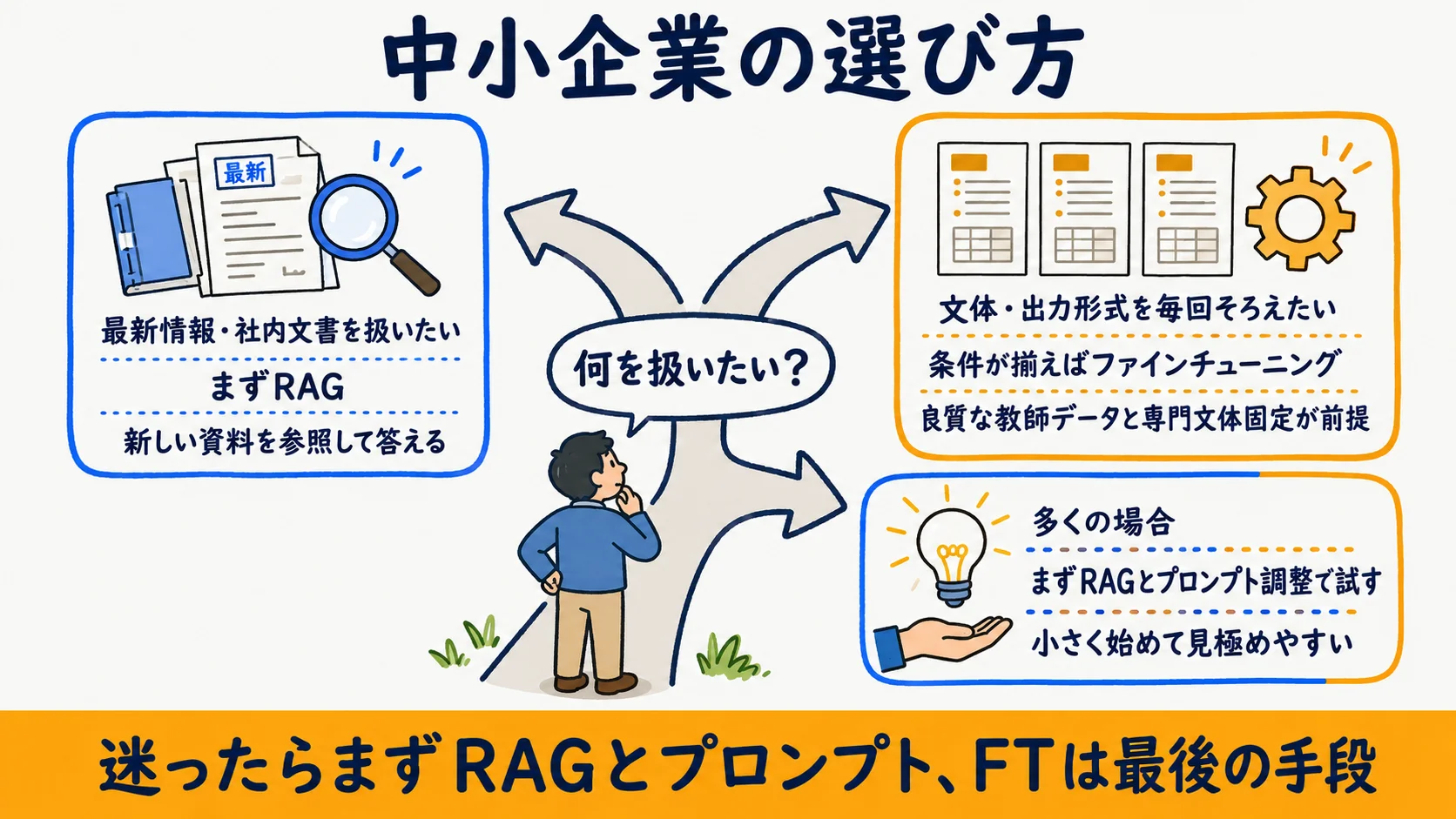
ファインチューニングが優位になったのは、専門文体やフォーマットの固定が必須・大量の良質な教師データが既に手元にある・低レイテンシ要件が厳しい、といった条件が揃ったときに限られた。逆に言えば、これらが揃わないうちは、RAGとプロンプト調整で要件を満たせるかを先に確かめるほうが、コストも運用負荷も抑えられる(当社AI編集部の定性観察・2026-06-25時点)。なお、自社で作るか外部に頼むかという内製/外注の事業判断は、RAGかFTかの技術選択とは別軸の話だ。その線引きは「AIエージェントは作るか買うか」で扱う。RAGはそもそも「AIエージェントとは」で扱う自律システムの構成部品の一つでもあり、手法単体ではなく全体設計の中で位置づけると判断しやすい。
まとめ
RAGとファインチューニングは、どちらが優れているかではなく、扱いたいのが「最新の事実」か「振る舞い」かで選ぶ。変わる情報・社内文書・出典提示・計算資源の制約があるならRAG、専門文体や出力形式の固定・特定タスクの安定で良質な教師データがあるならファインチューニングが起点になる。多くの実務では、まずRAGとプロンプトで足りるかを試し、足りない振る舞いだけをFTで補う併用が現実解だ。金額やパーセントなどの具体数値は変動が速いため本記事では断定せず、導入前に各社公式で最新を確認してほしい。RAGそのものの定義・仕組みの基礎は、別途のRAG解説で深掘りしていく。
手法選びの次に効く、全体設計の視点
RAGもファインチューニングも、それ単体ではなく「何を自動化したいか」から逆算すると迷いません。AIエージェントとは(仕組み・できること)とAIエージェントは作るか買うかも、導入前の判断材料に役立ちます。
よくある質問
- Q. RAGとファインチューニングの一番の違いは?
- 外部の知識ベースを「参照する」のがRAG、モデルの重み(weights)を更新して「振る舞いを変える」のがファインチューニング(FT)です。RAGは再学習せず最新情報を足せ、FTは特定タスクや文体を安定させます(出典: AWS/Microsoft Learn・2026-06-25時点)。
- Q. 最新情報や社内文書を扱いたいときはどちらを選ぶ?
- RAGが向きます。モデルを再学習せず(without retraining)に最新ソースを参照でき、出典提示やハルシネーション抑制にも向くためです。社内文書が頻繁に更新される、計算資源が限られる場合もRAGが基本です(出典: AWS/Microsoft Learn・2026-06-25時点)。
- Q. ファインチューニングで新しい知識を覚えさせられる?
- 新しい事実・知識の追加には不向きです。FTは分類・特定フォーマット生成・指示追従の改善など「どう振る舞うか(how)」を整える用途で、OpenAIは最適化を「評価→効果的なプロンプト→必要ならFT」の順で推奨しています(出典: OpenAI・2026-06-25時点)。
- Q. RAGとファインチューニングは併用できる?
- できます。形式・スタイルをFTで固定し、動的で最新の事実をRAGで載せる役割分担が代表的なハイブリッドです。OpenAIの推奨順でもまずプロンプトとRAGで足りるかを試し、必要に応じてFTを足す設計が現実的です(出典: Microsoft Learn/AWS/OpenAI・2026-06-25時点)。
- Q. 中小企業はどちらから始めるべき?
- 多くの場合まずRAGとプロンプト調整で足ります。FTは専門文体の固定・大量の良質な教師データが既にある・低レイテンシ要件、といった条件が揃ったときの選択肢です。作るか買うかの事業判断は技術選択とは別軸で考えます(当社AI編集部の定性観察・2026-06-25時点)。
出典・参考資料
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.