社内RAGチャットボットの作り方|構築4ステップと方式比較【2026】
一次ソース検証型AIメディア編集部 ・ 監修: 依田 尚人
目次
社内RAGチャットボットとは、社内の規定・マニュアル・FAQ といった文書をAIに検索させ、その内容を根拠にして答えさせる仕組みだ。作り方は (1)データ整備 (2)ベクトル化 (3)検索 (4)回答生成 の4ステップが基本で、実現方式はノーコード/Copilot Studio/Dify/自作RAG の中から要件で選ぶ。本記事は2026年6月25日時点の各社公式情報と当社の実務知見に基づき、特定の製品や方式を推さず中立に整理する。RAG の仕組みそのものの深掘りより、社内で動くボットを作るための判断軸と手順に絞る。
迷ったら、まず社内FAQ・規定の一次回答をノーコードや組み込みRAG(Copilot Studio・Dify 等)で小さく始め、独自の検索ロジック・厳格な権限分離・特殊な前処理が要る段階で自作RAGへ移すのが堅い。成否を分けるのは、食わせるデータの整備(ここが精度の大半を決める)と、ハルシネーション・情報漏洩を防ぐガードだ。データをモデル学習に使わない法人プランを選ぶことも最低ラインになる(2026-06-25時点)。
なお当社(YDAIコンサルティング AI編集部)は、16以上の事業で社内ナレッジ検索・RAGチャットボットを構築・運用してきた立場にある。そのうえで、本記事はどの製品も方式も勝たせず、用途別に中立に整理する。自社サービスへの送客は一切しない。
結論:RAGチャットボットとは何か・作り方は4ステップ・方式は要件で選ぶ
社内RAGチャットボットの作り方は、どの方式でも共通して「データ整備→ベクトル化→検索→回答生成」の4ステップに分解できる。違いは、この4ステップのどこまでを自分で持つかだ。ノーコードや組み込みRAGは中間2ステップを製品が隠蔽してくれ、自作RAGは全工程を自前で設計する。方式は大きく4択になる。社内FAQ向けのノーコード型、Microsoft 365 環境で組み込みRAGが使える Copilot Studio、ノーコードでLLMアプリを組める Dify、そしてAPIとベクトルDBを自前で構成する自作RAG だ。「どれが正解か」ではなく「自分の用途はどこに当たるか」で分岐する。一次回答だけならノーコードで足りることが多く、独自要件が重なるほど自作側に寄る。
そもそもRAG(検索拡張生成 / Retrieval-Augmented Generation)とは、企業データの検索と、取得した情報をLLMで統合するテキスト生成を組み合わせる設計パターンだ。モデルの記憶だけに頼らず、組織固有の根拠に基づいて回答を生成することで、誤情報を減らし信頼性を高める狙いがある(出典: Microsoft Learn・参照2026-06-25時点)。
社内データに効く理由は、学習データに含まれない自社固有の情報を「根拠付き」で答えられる点にある。一般的なチャットボットは社内規定を知らないが、RAG は質問のたびに社内文書を検索し、その内容だけを材料に回答を組み立てる。これがハルシネーション(事実に基づかない生成)の抑制につながる。ただし抑制であってゼロ化ではない。根拠に乏しい質問では誤りが残りうるため、過信しない設計が前提になる(出典: 大和総研 RAG解説・参照2026-06-25時点)。
MCP(ツール接続)との違い
RAG は「知識を参照する」手法であり、AIに外部ツールやデータ源を接続する仕組みである MCP とは別レイヤーの話だ。両者は補完関係にあり混同しやすいため、ツール接続の概念は「MCPとは(仕組み・できること)」を参照してほしい。本記事は知識参照側、つまり社内文書を検索して答えるRAGボットの作り方に集中する。
構築方式の比較早見表
方式選定は、主役となる仕組み・向く規模や用途・コスト感・権限と学習データの確認点・自作度の5観点で整理すると見通しが良い。下表は数値の断定を避け、料金は定性と参照日で扱う(料金体系は改定が速く、孤立した数値を独り歩きさせないため)。
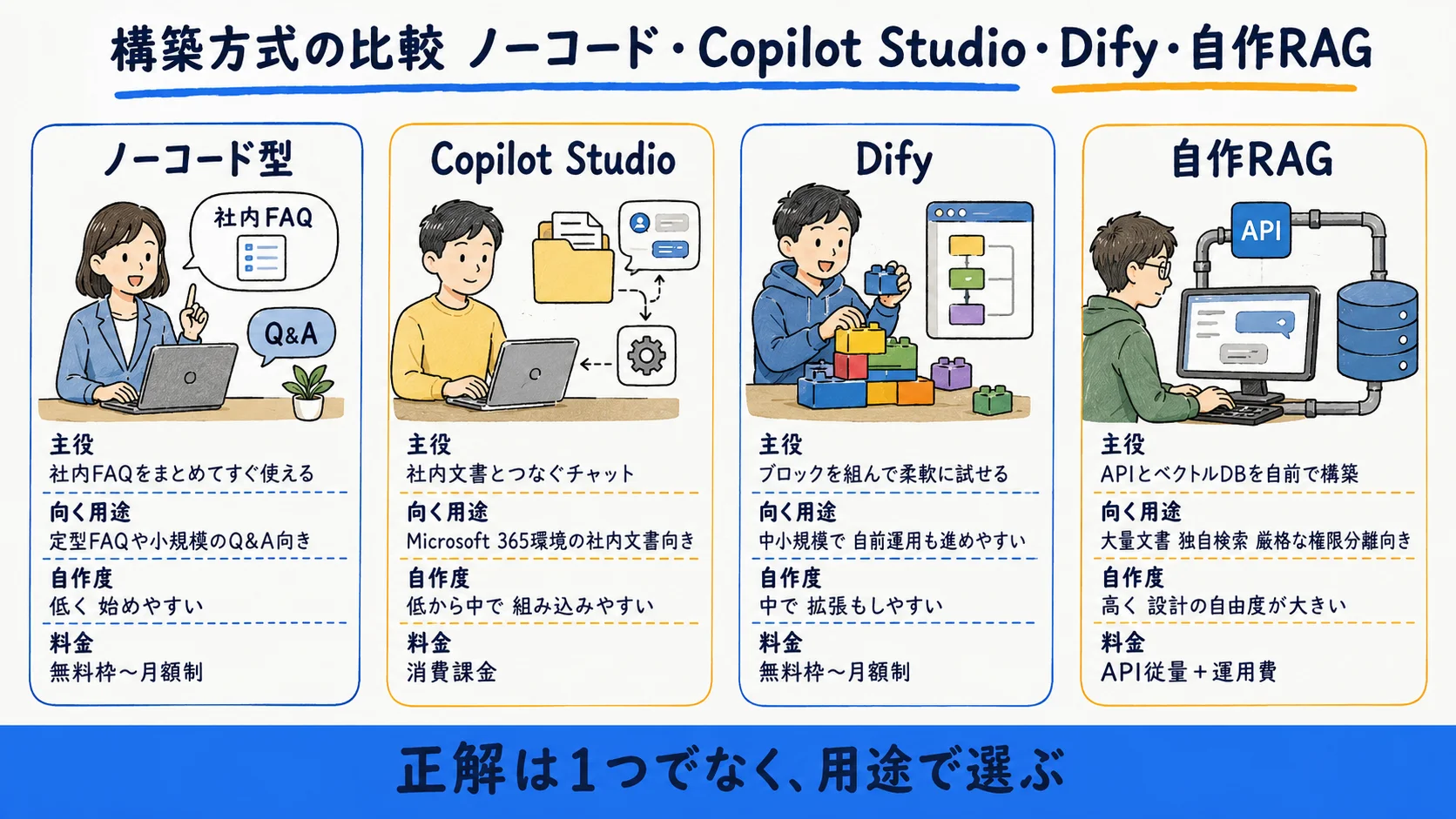
| 方式 | 主役 | 向く規模・用途 | コスト感(2026-06-25時点・公式参照) | 権限・学習の確認点 | 自作度 |
|---|---|---|---|---|---|
| ノーコード型 | 社内FAQ/Q&Aツール | 定型FAQ・小規模な一次回答 | 製品により無料枠〜月額制 | 学習利用の有無を要確認 | 低 |
| Copilot Studio | Microsoft 365 の組み込みRAG | 365環境・SharePoint等の社内文書 | 消費課金(従量・容量パック制) | データを学習に使わないと公式明記 | 低〜中 |
| Dify | ノーコードLLMアプリ基盤 | 中小規模・自前運用も可 | 無料枠あり/有料は月額制 | プラン・運用形態で要確認 | 中 |
| 自作RAG | API+ベクトルDBを自前構成 | 大量文書・独自検索・厳格な権限分離 | API従量+基盤運用費 | 自前で設計・全責任 | 高 |
Copilot Studio は RAG が組み込みで提供され、ナレッジソース(SharePoint・OneDrive、アップロードファイル、Dataverse、公開Web 等)を設定するだけで動く。独自の Azure AI Search 構築やコード記述は任意であり必須ではない(出典: Microsoft Learn・参照2026-06-25時点)。Dify の具体的な料金プランと操作手順は変動が速いため、本記事では中立に1行で並べるに留め、導入実務は各製品の公式情報で確認してほしい(出典: Dify 公式 Pricing・参照2026-06-25時点・要再確認)。
作り方4ステップ|データ整備から回答生成まで
RAGチャットボットの中身は、準備段階と実行段階に分かれる。準備段階で社内文書を検索可能な形に変換しておき、実行段階で質問のたびに関連文書を引いて回答を作る。業界標準として複数の独立した解説で構成が一致している(出典: lakeFS/Weaviate・参照2026-06-25時点)。
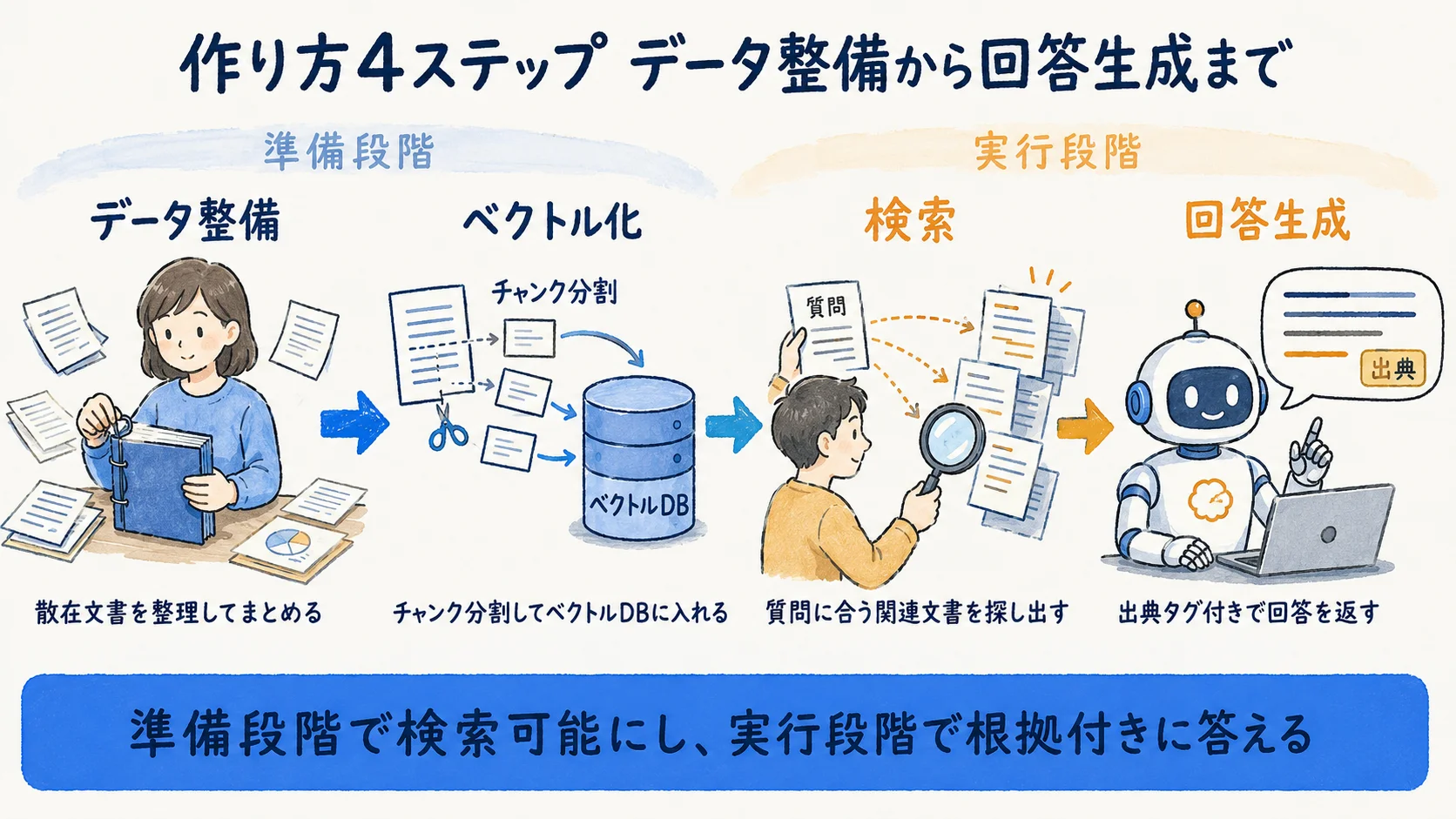
ステップ1:データ整備(準備段階)
検索対象にする社内文書を集め、正本を一本化し、不要な旧版や重複を取り除く。ここが後段の精度を左右する。詳細は次節で扱う。
ステップ2:ベクトル化(準備段階)
文書を適切な単位に分割(チャンク分割)し、それぞれを埋め込みモデルでベクトル化して、ベクトルDBに格納する。分割の粒度が検索精度に影響するため、文書構造に合わせて調整する(出典: Weaviate・参照2026-06-25時点)。
ステップ3:検索(実行段階)
ユーザーの質問を同じ方式でベクトル化し、類似度検索で関連する文書を上位から取得する。Copilot Studio では各ナレッジソースから上位数件を取得する設計が公式に示されている(出典: Microsoft Learn・参照2026-06-25時点)。
ステップ4:回答生成(実行段階)
取得した文書を質問に結合し、LLM が出典付きで回答を生成する。Copilot Studio の場合はクエリ書き換え・コンテンツ取得・要約と回答生成・安全性とガバナンス検証の流れで提供される(出典: Microsoft Learn・参照2026-06-25時点)。ノーコードや組み込み方式では、このうちベクトル化と検索が製品内に隠蔽され、利用者はデータ登録と設定に集中できる。全工程を自前で持つのは自作RAG だけだ。
食わせるデータの選定と前処理|精度の大半を決める
当社が16以上の事業で社内RAGボットを運用してきた現場感覚として、回答精度の大半はモデルやベクトルDBの選択ではなく、食わせるデータの整備で決まる。同じ仕組みでも、入れる文書の質で体感がはっきり変わる。
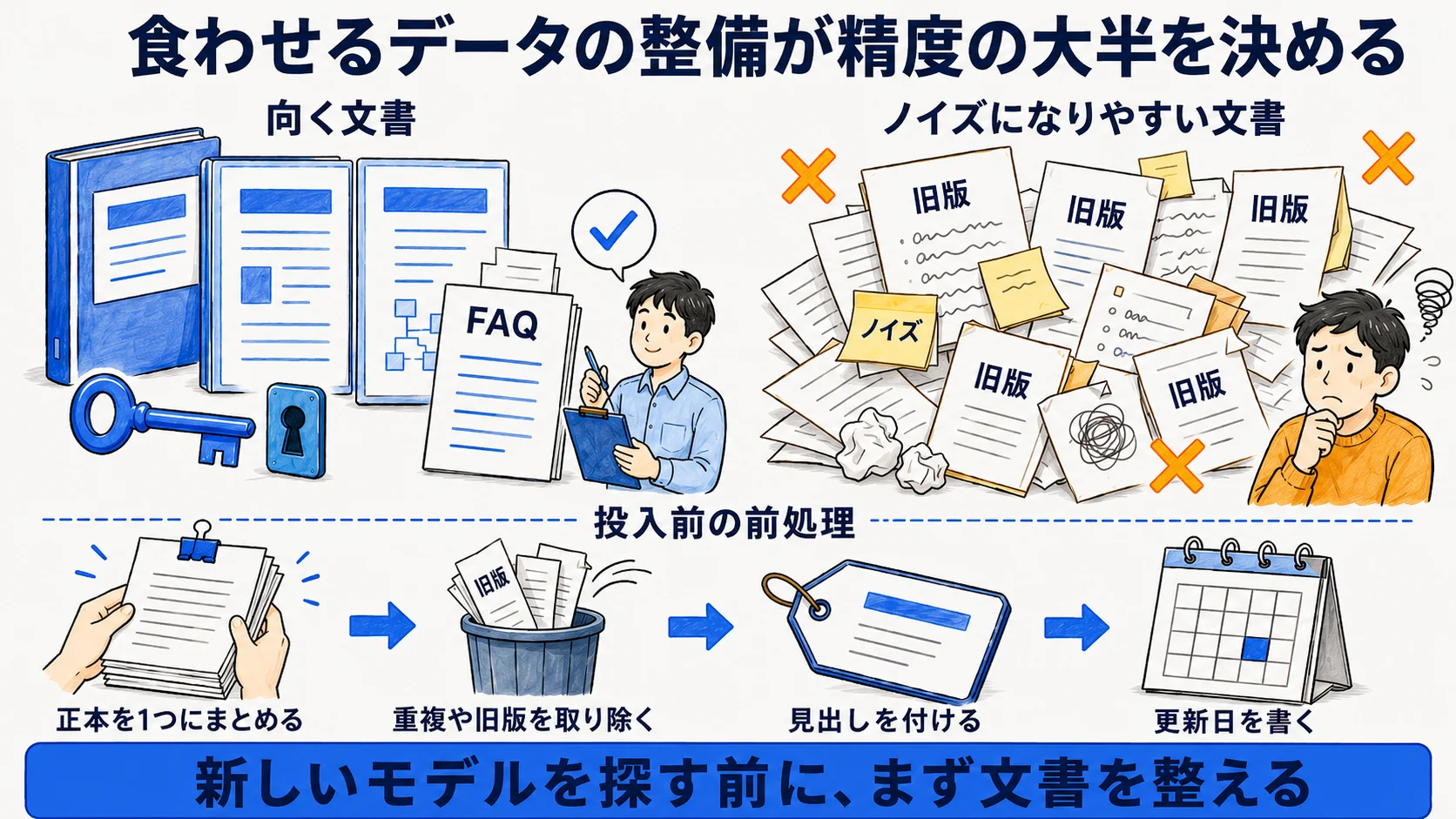
向くのは、構造化された規定・FAQ・手順書のように「1つの問いに1つの正解」が紐づく文書だ。逆にノイズになりやすいのは、口語のままの議事録や、バージョンが散在して旧版と新版が混在した文書である。これらは類似度検索で誤った断片を引き、古い情報や文脈のずれた回答を生みやすい。
投入前の前処理として、正本の一本化・重複や旧版の除去・見出しの付与・更新日の明記を行うだけで、回答の安定感が大きく変わる。見出しが整理された文書はチャンク分割の境界が自然になり、検索の的中率が上がる。新しいモデルを探す前に、まず手元の文書を整える。これが社内RAG構築でいちばん費用対効果の高い投資になる。
ハルシネーション・情報漏洩を防ぐガード
社内RAGボットで起きやすい事故は、誤った回答(ハルシネーション)と、見せてはいけない文書を見せてしまう情報漏洩の2系統だ。どちらも構築時に手当てしておく。
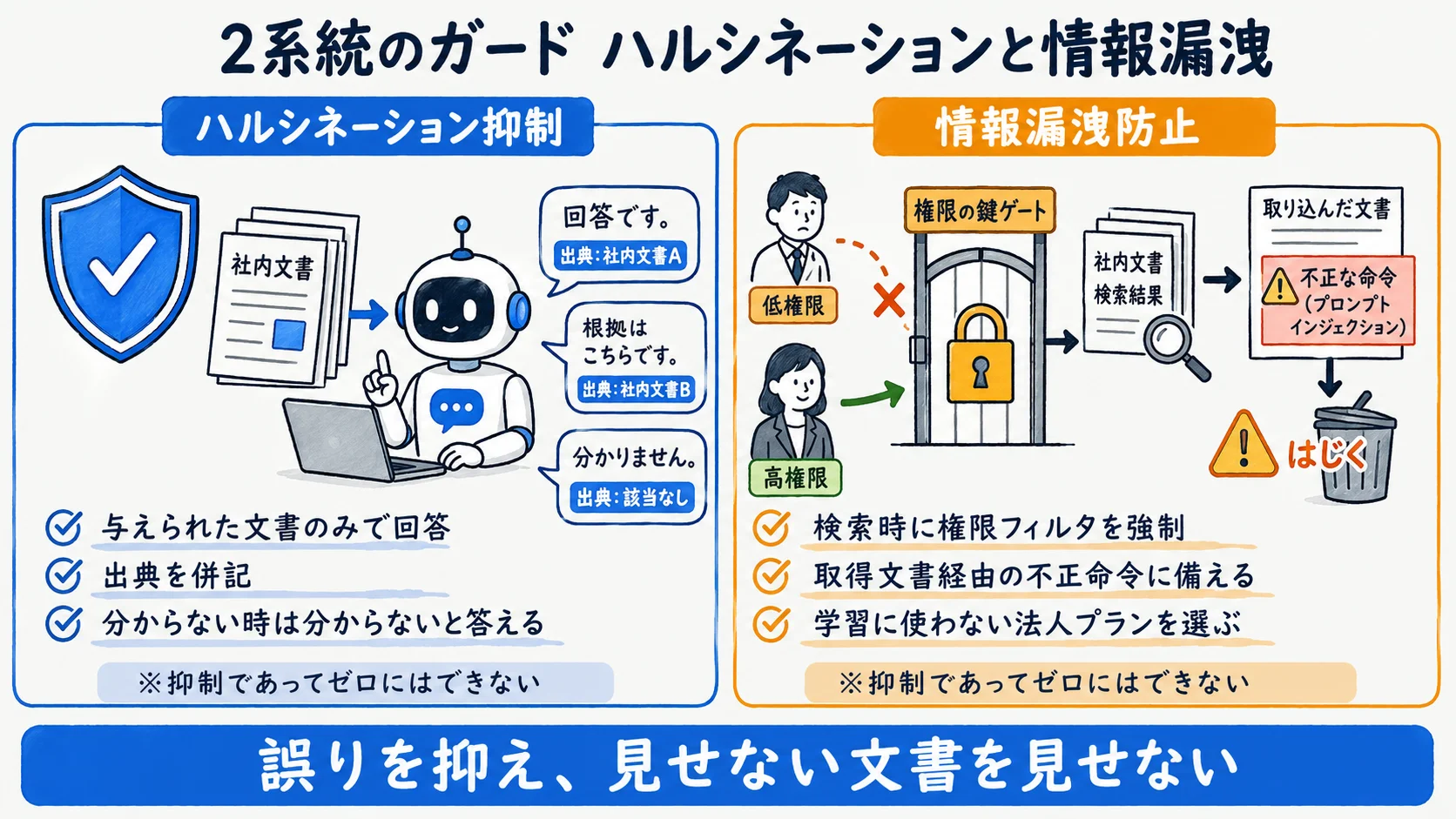
ハルシネーション側は、「与えられた文書のみを使って回答する」とプロンプトで明示し、回答に出典を併記させ、根拠が見つからない時は「分かりません」と答えさせるのが定石だ。これは抑制策であってゼロ化ではない点を運用者が理解しておく必要がある(出典: 大和総研 RAG解説・Microsoft Learn・参照2026-06-25時点)。
情報漏洩側で見落とされやすいのが、検索時の認可だ。ベクトルDBに入れただけでは安全にならない。検索が関連度スコアだけで文書を選び、クエリ時に認可を強制しないと、低権限のユーザーが本来見られない文書を取得してしまう。あわせて、取得した文書に悪意ある命令を仕込む間接プロンプトインジェクションや、ベクトルDBへの不正データ混入(ポイズニング)も主要リスクとして挙げられている(出典: OWASP Gen AI Security Project LLM01・参照2026-06-25時点)。クエリ時の権限フィルタを多層防御の一部として必ず組み込む。
最後に、データをモデルの学習に使わない法人グレードのプランを選ぶことも基本になる。例えば Copilot Studio は、データをモデル学習に使わないと公式に明記している(出典: Microsoft Learn・参照2026-06-25時点)。全社的な生成AIの統制・利用ポリシー策定やシャドーAI対策といった横断テーマは「生成AIのセキュリティリスクと社内対策」に委譲し、本記事はRAG構築固有のガードに絞る。
運用・改善|フィードバックループで育てる
社内RAGボットは公開して終わりではなく、使われながら精度を上げていく。回答ログと「役に立った/立たなかった」の評価を集め、答えられなかった質問を洗い出し、不足していた文書の追加や前処理の見直しに反映する。これを定期的に回すフィードバックループが、放置で陳腐化するボットと育つボットを分ける。
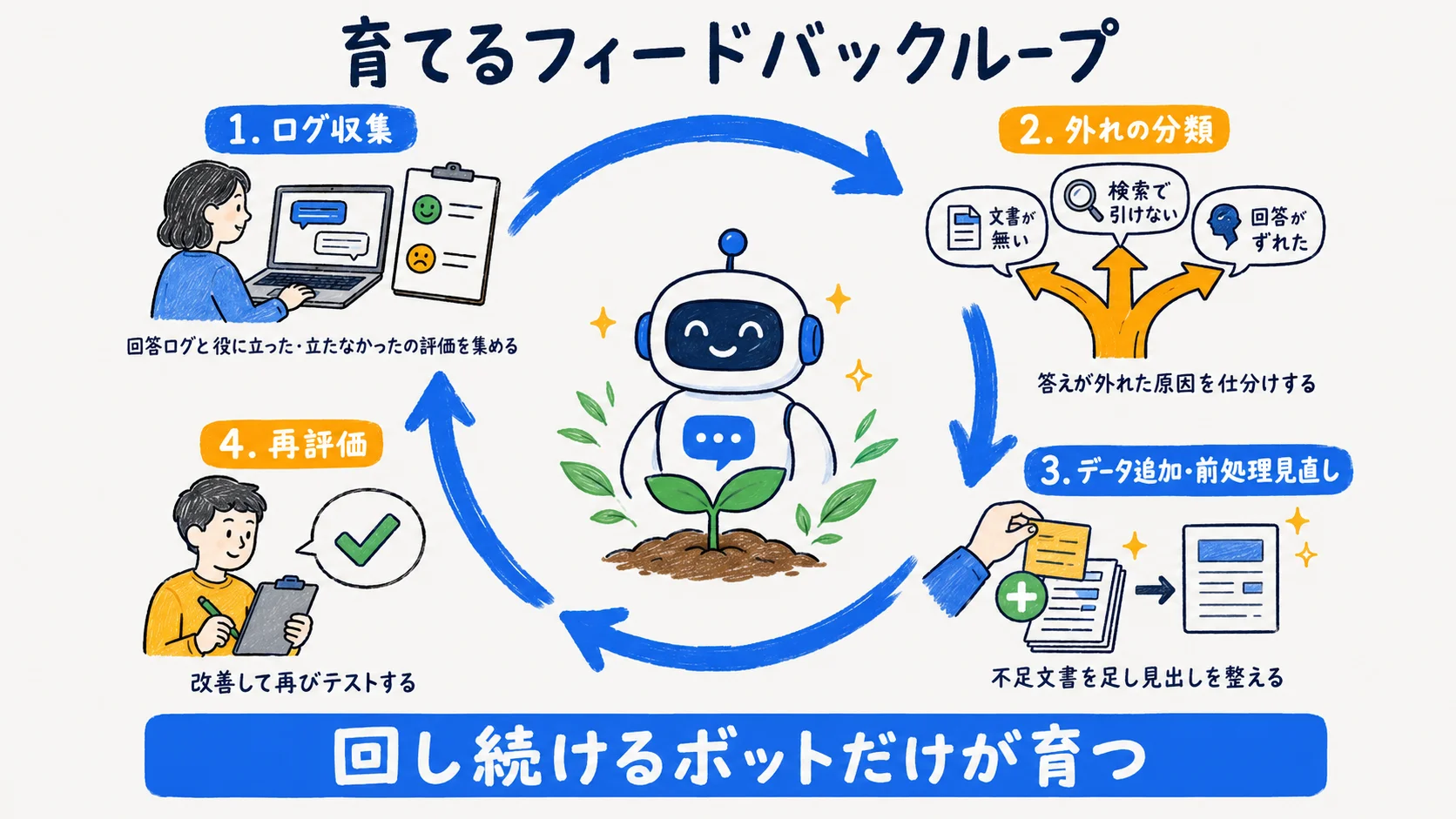
評価の起点は、回答が外れたケースの分類だ。文書が無くて答えられなかったのか、文書はあるのに検索で引けなかったのか、引けたのに回答がずれたのかで打ち手が変わる。1つ目はデータ追加、2つ目はチャンク分割や見出しの見直し、3つ目はプロンプトの調整に対応する。問い合わせ対応そのものの設計や運用KPIの考え方は「カスタマーサポートAI活用ガイド」に、社内AI導入の全体的な進め方は「中小企業が社内AIを導入する5ステップ」に詳しいので、用途運用の設計はそちらを参照してほしい。
まとめ
社内RAGチャットボットの作り方は、どの方式でも「データ整備→ベクトル化→検索→回答生成」の4ステップに集約される。方式に唯一の正解はなく、用途で分岐するのが結論だ。社内FAQ・規定の一次回答ならノーコードや組み込みRAG(Copilot Studio・Dify 等)から小さく始め、独自の検索ロジック・大量文書・厳格な権限分離が必要になった段階で自作RAGへ寄せる。成否を分けるのは食わせるデータの整備と、ハルシネーション・情報漏洩を防ぐガードであり、データを学習に使わない法人プランを選ぶことも欠かせない。どれを選んでも、根拠付きで誤りを抑える設計から外れないことが社内活用の前提になる(2026-06-25時点)。
社内RAGの前後関係もあわせて押さえる
社内AI導入の全体像から整理したい方は「中小企業が社内AIを導入する5ステップ」、構築時に欠かせないセキュリティ統制は「生成AIのセキュリティリスクと社内対策」もあわせてどうぞ。
よくある質問
- Q. 社内RAGチャットボットはノーコードで作れますか?
- 社内FAQ・規定の一次回答ならノーコードや組み込みRAG(Copilot Studio・Dify 等)で作れることが多いです。独自の検索ロジック・大量文書・厳格な権限分離が必要な場合は自作RAGを検討します(2026-06-25時点)。
- Q. RAGチャットボットでハルシネーションはなくせますか?
- ゼロにはできませんが抑制できます。社内文書を根拠に「与えられた情報のみで回答」させ、出典を提示し、分からない時は分からないと答えさせるのが定石です(出典: Microsoft Learn・大和総研 RAG解説・参照2026-06-25時点)。
- Q. RAGチャットボットの作り方の基本ステップは?
- (1)データ整備 (2)ベクトル化(チャンク分割→埋め込み→ベクトルDB格納) (3)類似度検索で関連文書を取得 (4)取得文脈と質問でLLMが出典付きで回答、の4ステップです。ノーコードや組み込み方式では(2)(3)が製品内に隠蔽されます(出典: lakeFS/Weaviate・参照2026-06-25時点)。
- Q. RAGチャットボットで情報漏洩を防ぐには?
- 取得時に権限フィルタを強制し(関連度だけで文書を出さない)、取得文書経由の間接プロンプトインジェクションに備え、学習に使われない法人プランを選びます(出典: OWASP Gen AI Security Project LLM01・参照2026-06-25時点)。
- Q. RAGチャットボットの精度を上げる一番のコツは?
- 食わせるデータの整備です。構造化された規定・FAQ・手順書はRAG適性が高く、口語の議事録や旧版が散在する文書はノイズになりやすいため、正本の一本化・重複や旧版の除去・見出し付与を先に行います(当社AI編集部の実務知見・定性)。
出典・参考資料
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.