RAGとは?検索拡張生成の仕組みと社内活用をやさしく解説【2026】
一次ソース検証型AIメディア編集部 ・ 監修: 依田 尚人
目次
RAG(検索拡張生成)という言葉を最近よく見るが、「結局なにをする仕組みなのか」「自社の文書で使えるのか」がつかみにくい。本記事は2026年6月25日時点の各社公式情報をもとに、RAGの定義・仕組み・使い分け・社内文書での向き不向きを、特定の製品を推さず中立にやさしく整理する。専門用語は最小限にし、導入の当たりをつけられることをゴールにする。
RAGとは、外部の知識ベースを検索し、その内容を踏まえてLLMが回答を生成する仕組みである。モデルを再学習せず、最新の情報や社内の専有データを「参照」させられるのが核心だ。万能ではなく、検索でヒットしなければ答えられず、元の文書が古い・矛盾していれば誤った回答が伝播する。まず向いている文書(規定・FAQ・手順書)から小さく始め、人の最終確認を残すのが堅い使い方になる(2026-06-25時点)。
なお当社(YDAIコンサルティング AI編集部)は16以上の事業で社内ドキュメント(議事録・規定・手順書など)を日常的に運用し、AI導入の受託も行う立場にある。そのうえで、本記事はどのRAG製品・ベクトルデータベース・LLMベンダーも勝たせず中立に整理する。自社サービスへの送客は一切しない。
RAGとは(結論定義)
RAGは Retrieval-Augmented Generation(検索拡張生成)の略で、LLMが訓練データの外にある「権威ある知識ベース」を参照してから回答を生成するプロセスを指す。AWSは公式に「大規模言語モデルの出力を最適化し、回答を生成する前に、訓練データの外にある権威ある知識ベースを参照させること」と定義している(出典: AWS「What is RAG」・参照2026-06-25時点)。
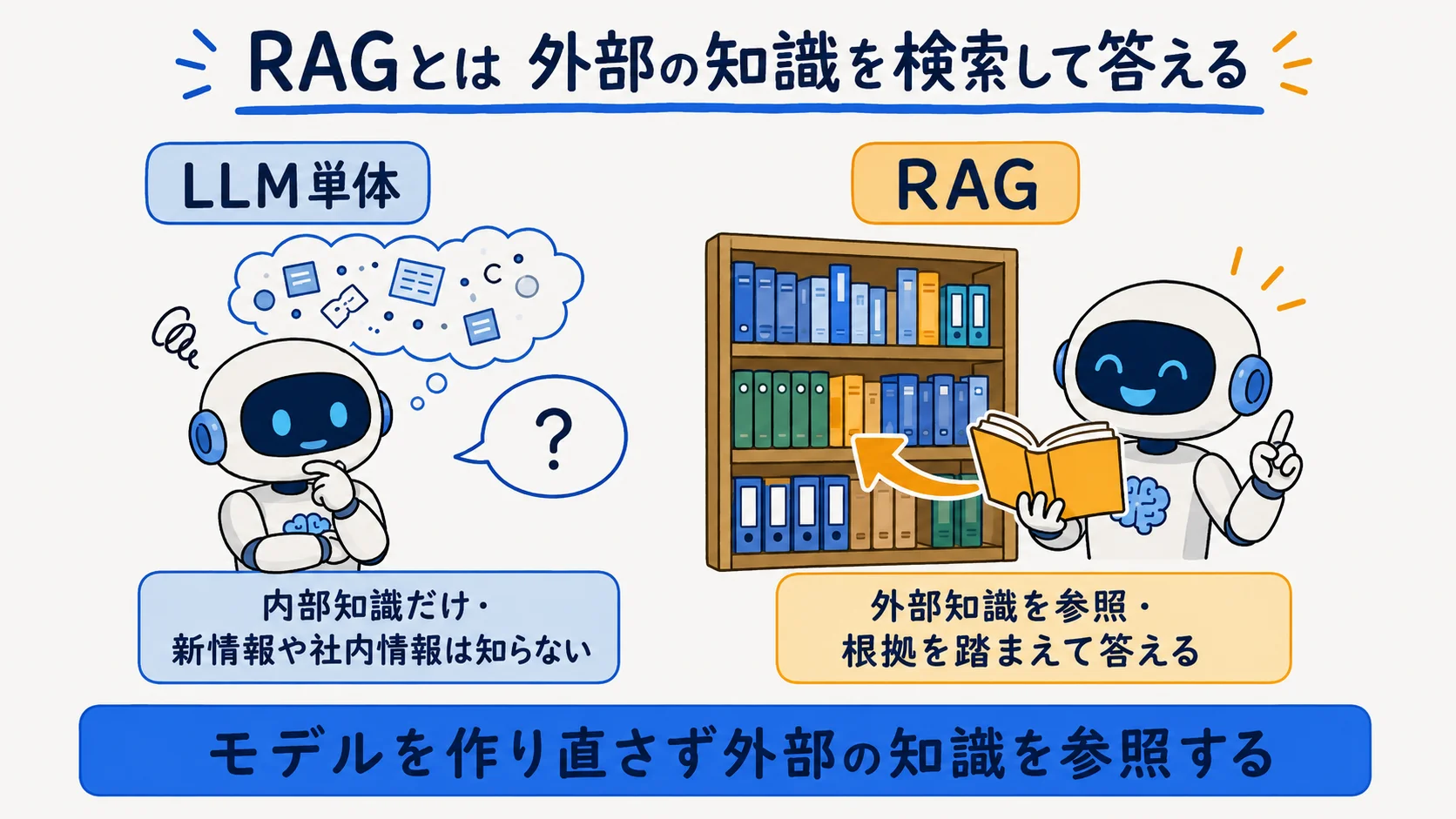
ポイントは、モデルそのものを作り直さない点にある。LLM単体は学習済みの「内部知識」だけで答えるため、学習後の新情報や社内限定の情報は知らない。RAGはそこに外部知識という「カンニングペーパー」を渡し、根拠を踏まえて答えさせる。「RAG」という語と手法自体は、2020年にMeta(当時はFacebook AI Research)の研究者らが発表した論文で提唱された比較的新しい概念だ(出典: Lewis et al. NeurIPS 2020・参照2026-06-25時点)。事前学習済みの記憶に、外部の索引を検索する仕組みを組み合わせる、という考え方が原型になっている。
早見表|RAG・ファインチューニング・プロンプトの違い
LLMに知識を持たせる・賢く使う方法は、RAGだけではない。よく比較されるのが「プロンプト(指示の工夫)」と「ファインチューニング(再学習)」だ。3つの違いを1枚で押さえておくと、RAGがどの場面で効くのかが見えてくる。
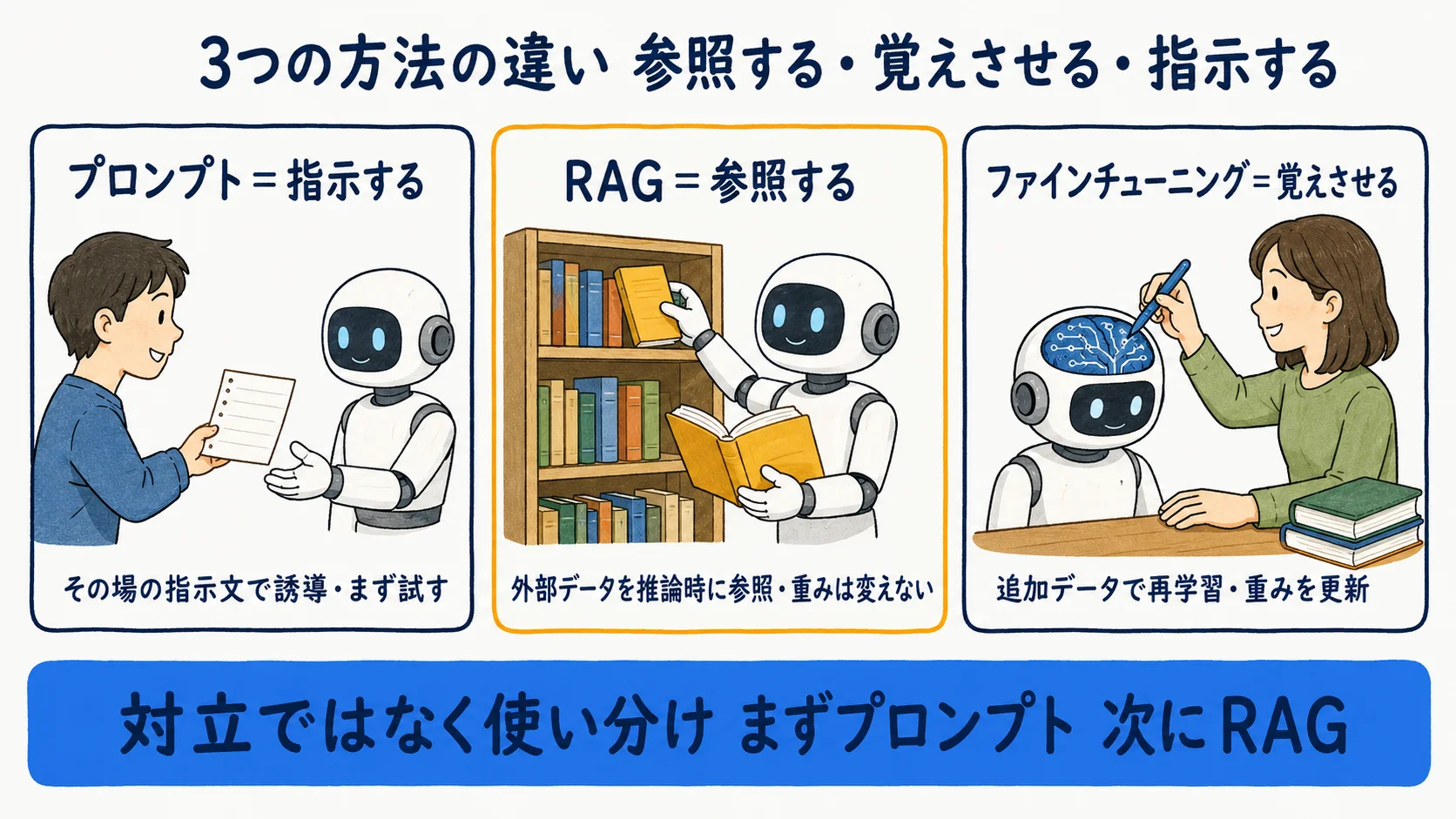
| 手法 | やること | 知識の入れ方 | 更新の手間 | 向く場面 |
|---|---|---|---|---|
| プロンプト | 指示や例示で出力を誘導 | その場の指示文に含める | 都度書き換え(軽い) | まず試す・少量の前提共有 |
| RAG | 外部データを推論時に参照 | 検索で動的に渡す(重みは変えない) | 文書を差し替えるだけ | 最新性・社内文書・出典提示が要る |
| ファインチューニング | 追加データで再学習 | モデルの重みを更新 | 再学習が必要(重い) | 文体・振る舞い・専門口調の固定 |
一般には「まずプロンプトで試し、限界が来たらRAGで外部知識を足し、それでも足りなければファインチューニング」という順序が定石とされ、2026年時点の本番システムでは3手法を併用する構成も主流とされる(出典: IBM「RAG vs. fine-tuning vs. prompt engineering」・参照2026-06-25時点)。RAGとファインチューニングの「どちらを選ぶか」の深掘りは別記事で扱う予定で、ここでは「RAG=参照/ファインチューニング=覚えさせる/プロンプト=指示する」という大枠の違いを押さえておけば十分だ。
RAGの仕組み(検索→生成の4ステップ)
RAGの中身は、大きく「事前の文書準備」と「質問時の検索→生成」の2フェーズに分かれる。AWSはこの動作を、検索(Retrieval)・付与(Augmentation)・生成(Generation)の3段で説明している(出典: AWS「What is RAG」・参照2026-06-25時点)。準備フェーズを足して、4ステップで具体的に見る。
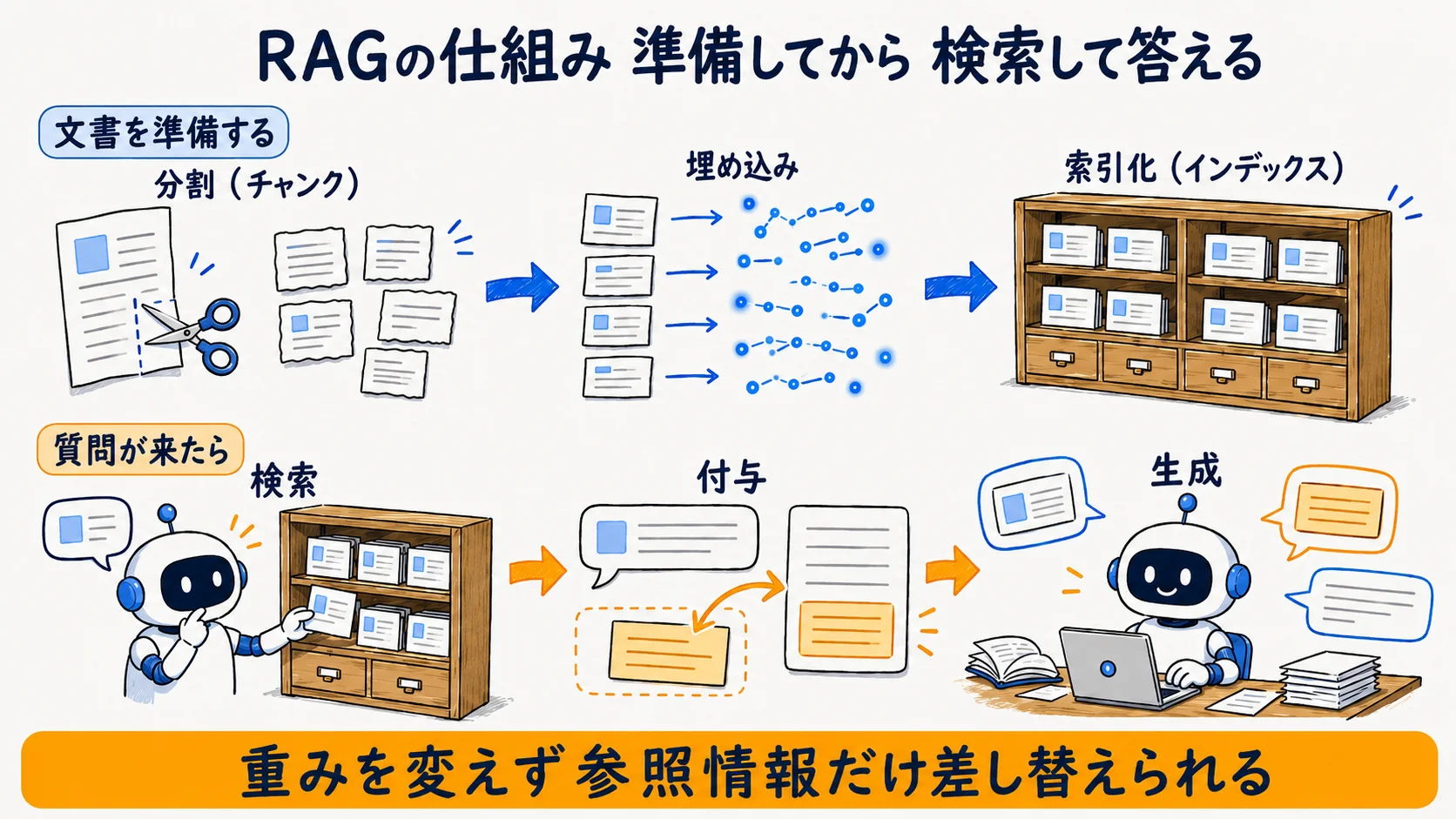
ステップ1 文書を準備する(分割→埋め込み→索引化)
まず社内文書やマニュアルを、検索しやすい形に整える。文書を意味のまとまりごとに区切り(チャンク分割)、必要に応じてメタデータを付け、埋め込みモデルでベクトル(数値の並び)に変換し、検索用の索引に格納する。マイクロソフトはこの一連の流れを業界標準のアプローチと位置づけている(出典: Microsoft Learn「Design and develop a RAG solution」・参照2026-06-25時点)。分割の粒度は、細かすぎると文脈が失われ、粗すぎると検索ノイズが増える。一般的な目安は「数百〜千字程度」「文意の切れ目」で区切ることだが、最適値は文書の性質次第なので、ここでは数値を断定しない(粒度の具体値はベンダー解説の目安であり一次情報ではないため・公式参照・要再確認2026-06-25時点)。
ステップ2〜4 検索→付与→生成
質問が来たら、その質問もベクトルに変換し、索引から意味的に近いチャンクを検索する(検索)。見つかった内容を、質問とあわせてプロンプトに「文脈」として付け足す(付与)。最後に、LLMがその外部情報と自身の訓練知識を踏まえて回答を組み立てる(生成)。この流れにより、モデルを再学習しなくても、渡す文書を入れ替えるだけで参照先を更新できる。RAGの運用が比較的軽いとされるのは、この「重みを変えずに参照情報だけ差し替える」構造のためだ。
なぜ今RAGなのか
LLMをそのまま使うと、(1)学習後の最新情報を知らない、(2)社内限定の情報を答えられない、(3)それらしい誤情報(ハルシネーション)を出す、という弱点が出る。RAGはこの3点に効くため注目されている。AWSはRAGの便益として、基盤モデルを再学習せず新データを導入できるコスト効率、最新ソースに接続できる鮮度、誤情報や非権威ソースの引用を緩和するハルシネーション抑制、回答に引用を付けて検証可能にする出典帰属の4点を挙げている(出典: AWS「What is RAG」・参照2026-06-25時点)。
とりわけ社内活用で効くのが、最新性と運用の容易さだ。規程が改定されたら該当文書を差し替えるだけで参照先が更新され、モデルを作り直す必要がない。社内の規程集・議事録・技術資料から意味的に関連する情報を検索して答えに反映できるため、多くの業務利用でRAGが最初の選択肢になりやすい(出典: 大和総研「RAG(検索拡張生成)とは?」・参照2026-06-25時点)。学習コストの高いファインチューニングに踏み込む前の、現実的な第一歩として位置づけられる。
RAGのメリットと限界(過信しない)
RAGの強みは、最新・専有の情報を低コストで参照でき、回答に出典を付けて検証可能性を高められる点にある。一方で、RAGを「魔法の正答装置」と過信するのは危険だ。限界を正しく知っておくほうが、結果的に使いこなせる。
第一に、検索でヒットしなければ答えられない。索引に該当情報がない、あるいは検索が外せば、LLMは外部根拠なしで答えてしまい、かえって誤りを補強することすらある。第二に、元の文書が古い・矛盾していると、その誤りがそのまま回答に伝播する。RAGは参照元の品質を超えられない。第三に、チャンク分割や前処理の設計で精度が大きく左右される。つまりRAGの良し悪しは「モデルの賢さ」より「渡す文書とその整え方」で決まる部分が大きい。社内AIで失敗しやすい落とし穴は社内AI導入でよくある失敗でも整理しているので、導入前にあわせて確認しておきたい。出典提示で検証はしやすくなるが、最終確認を人が担う運用は依然として欠かせない。
どんな社内文書がRAGに向くか(実務観察)
ここからは、当社(YDAIコンサルティング AI編集部)が16以上の事業で社内ドキュメント(議事録・規定・手順書・運用ルール)を日常運用してきた実務からの定性的な観察を述べる(数値ではなく傾向の共有であり、出所は当編集部の社内運用である)。
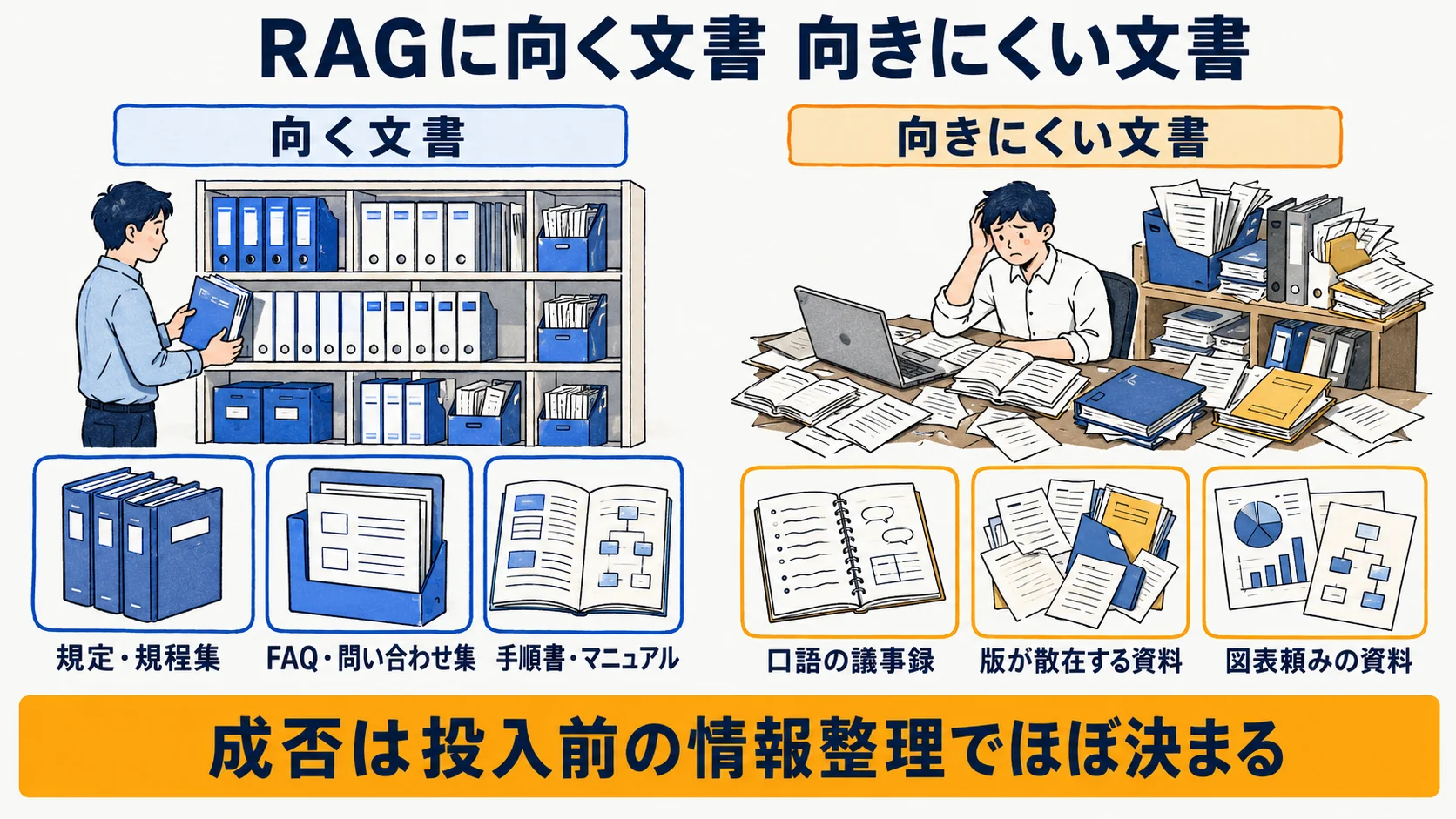
| 向く文書 | 向きにくい文書 |
|---|---|
| 規定・規程集(1項目1ルールで分割しやすい) | 口語の議事録(要点と雑談が混在しノイズ化) |
| FAQ・問い合わせ集(質問単位で完結) | 版が散在する資料(古い版が誤って検索される) |
| 手順書・マニュアル(手順が章立て) | 図表頼みの資料(テキスト化されず検索に乗らない) |
向くのは、構造化されていて「1項目1概念」で切り分けやすい文書だ。規定・FAQ・手順書は、そもそも人間が読む時点で項目が独立しているため、チャンク分割と相性がよく検索精度が出やすい。逆に、口語の議事録や、同じテーマの資料が複数バージョン散らばっている状態は、検索ノイズや「古い版を引いてしまう」誤答の温床になる。実感として、RAGの成否は「投入前の情報整理」でほぼ決まる。当社が運用ルールを1ファイル(CLAUDE.md)に集約し、AIに都度参照させている運用は、まさに「外部知識を都度参照する」というRAG的な発想の身近な実例でもある。投入前に、最新版を1つに定め、不要な重複を削ぐ。この地ならしが、どの製品を選ぶかよりも効く。
導入の全体像(次の一歩)
最後に、RAGを社内で試す際の進め方を方向性として示す。具体的な構築手順は本記事の範囲を超えるため、ここでは「どう始めるか」の地図だけを描く。
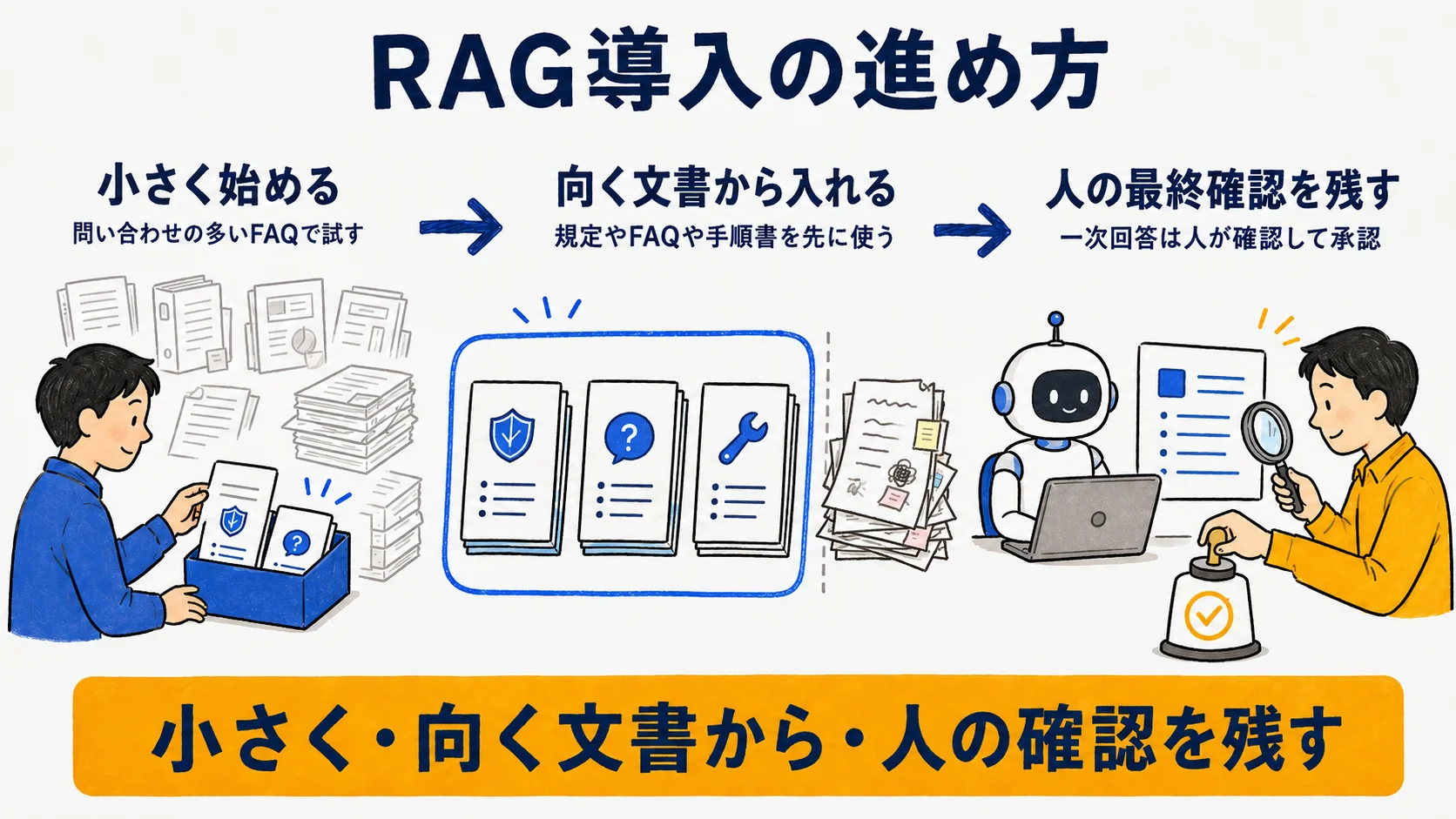
要点は3つだ。第一に、小さく始める。全社の全文書をいきなり投入せず、問い合わせの多いFAQや特定部署の手順書など、範囲を絞って試す。第二に、向く文書から入れる。前章のとおり、構造化された規定・FAQ・手順書を優先し、議事録などノイズ源は後回しにする。第三に、人の最終確認を残す。RAGは下書きや一次回答を高速に作るのは得意でも、誤りをゼロにはできないため、回答を人がチェックする運用を初期は必ず置く。中小規模での進め方は中小企業の社内AI導入5ステップが参考になる。なお、RAGはより広い「AIエージェント」の構成部品の一つでもある。RAGが外部知識を検索して回答に付与する「機能」であるのに対し、エージェントは計画・実行・検証を自律的に回す「仕組み」であり、両者の関係はAIエージェントとはで整理している。
まとめ
RAGとは、外部の知識ベースを検索し、その内容を踏まえてLLMが回答を生成する仕組み(検索拡張生成)だ。モデルを再学習せず最新・専有の情報を参照でき、出典を付けて検証可能性を高められるのが強みになる。一方で万能ではなく、検索でヒットしなければ答えられず、元文書の古さや矛盾は誤答として伝播する。社内で使うなら、規定・FAQ・手順書など構造化された文書から小さく始め、投入前の情報整理と人の最終確認を欠かさないことが成否を分ける。RAG・ファインチューニング・プロンプトは対立ではなく使い分けであり、まずRAGで足場を作るのが現実的な第一歩になる(2026-06-25時点)。
RAGを「自社で使えるか」を確かめる次の一歩
まずは向いている文書から小さく試すのが堅実です。社内AIでつまずきやすい点は社内AI導入でよくある失敗、中小規模での進め方は中小企業の社内AI導入5ステップもあわせてご覧ください。
よくある質問
- Q. RAGとは何ですか?
- RAG(Retrieval-Augmented Generation/検索拡張生成)は、外部の知識ベースを検索し、その内容を踏まえてLLMが回答を生成する仕組みです。モデルを再学習せず、最新の情報や社内の専有データを参照できるのが特徴です(出典: AWS「What is RAG」・2026-06-25時点)。
- Q. RAGとファインチューニングは何が違いますか?
- RAGは推論時に外部データを「参照」する手法でモデルの重みは変えません。ファインチューニングは追加データで再学習し重みを更新します。最新性や出典提示が要るならRAG、文体や振る舞いの固定ならファインチューニングが向くと一般に整理されます(2026-06-25時点)。
- Q. RAGを使えばハルシネーション(誤情報)はなくなりますか?
- 抑制はできますが、ゼロにはなりません。検索でヒットしない、元の文書が古い・矛盾していると、誤った回答が伝播します。引用(出典)を付与できるため、利用者が回答を検証しやすくなる利点はあります(出典: AWS「What is RAG」・2026-06-25時点)。
- Q. どんな社内文書がRAGに向きますか?
- 規定・FAQ・手順書など、構造化されて1項目1概念で分割しやすい文書が向きます。口語の議事録や版が散在する資料は検索ノイズになりやすく、投入前の情報整理が重要です(YDAIコンサルティング AI編集部の社内運用観察・定性)。
- Q. RAGとAIエージェントの関係は?
- RAGは外部知識を検索して回答に付与する「機能」です。AIエージェントはRAGを構成部品の一つとして使う、より広い「計画→実行→検証」を回す仕組みです(本媒体「AIエージェントとは」参照・2026-06-25時点)。
出典・参考資料
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.