AIエージェントとは?仕組み・種類・できること徹底解説【2026】
一次ソース検証型AIメディア編集部 ・ 監修: 依田 尚人
目次
- この記事の要点早見表
- AIエージェントとは
- 一言でいうと
- ワークフロー型と自律型の違い
- チャットボット・RAGとの違い
- 仕組み(どう動くのか)
- 中核は拡張されたLLM
- 計画→実行→検証→反復のループ
- 計画の質が成否を分ける
- 外部接続の標準プロトコル
- なぜ賢く動くのか
- 種類・分類
- 動作様式で分ける(ワークフロー型と自律型)
- 単体かチームか(シングルとマルチ)
- 動く場所で分ける(マネージドと自前構築)
- 接点で分ける(インターフェース)
- できること・できないこと
- できること(ベンダー公表のプロダクト仕様)
- できないこと・限界(独立した一次研究にもとづく)
- 限界をどう囲うか
- 導入の全体像(中小・中堅企業の現実)
- まずワークフロー型から始める
- 限界を人手レビューと承認で囲う
- ツール権限は運用ルールで縛る
- 具体的な導入手順は5ステップ記事へ
「AIエージェント」という言葉は毎日のように目にするのに、いざ説明しようとすると手が止まる。チャットボットと何が違うのか、RAGとは別物なのか、結局のところ何ができて何ができないのか——輪郭がぼやけたまま流行語だけが先行している、というのが多くの人の実感ではないだろうか。
先に結論を述べる。AIエージェントとは、大規模言語モデル(LLM)を頭脳として外部ツールを呼び出しながら、与えられた目標に向けて次の行動を自分で決めて実行するソフトウェアシステムである。単発の質問応答や、知識を検索して回答に足すだけの仕組みとは、ここで一線を画す。
本記事は2026年5月時点の公式仕様と一次研究(arXiv)に基づき、特定ベンダーの宣伝を排して中立に整理する。なお定義や分類は論者によって線引きが異なるため、本記事はAnthropicが提唱する整理を共通の言語(主軸)として用いつつ、Google・Microsoftの仕様や学術研究も照らし合わせて全体像を示す。
AIエージェントとは、LLMを頭脳に外部ツールを使い、目標達成へ向けて「計画→実行→検証→反復」というループを自ら回すシステムを指す。単発応答のチャットボットや検索補助のRAGと異なり、行動の選択を自己決定する点に本質がある。ただし自律性の程度には幅があり、人間が定めた経路を辿るワークフロー型から、LLMが経路を動的に決める自律型まで連続的に分布する。
この記事の要点早見表
| 観点 | 要点 | 出典 |
|---|---|---|
| 定義 | LLMを頭脳に、ツールを使い、目標へ向けて行動を自己決定するシステム | Anthropic 主軸/複数ソースで相対化 |
| 2タイプ | 経路を人間が定めるワークフロー型と、LLMが動的に決める自律型に分かれる | Anthropic 主軸/複数ソースで相対化 |
| 仕組みの核 | 計画→実行→検証→反復のループを、検索・ツール・記憶で拡張したLLMが回す | Anthropic「Building effective agents」 |
| 性能の決め手 | 賢さを左右するのは投入トークン量より、実行環境が返すフィードバックの質(決定係数 R² で説明力に大差) | arXiv:2605.29682 |
| できること | コード生成・PC操作・調査・長時間タスクの一部自動化(各ベンダー公表のプロダクト仕様) | Anthropic/Google/Microsoft 各社公表 |
| できないこと | 長時間の一貫性・完全自律・複雑判断の信頼性に限界(一次研究) | 代表例 arXiv:2605.29893 ほか(各限界の1対1出典は本文表) |
| 中小の第一歩 | 小さく区切り、人間確認を残し、社内業務から始める | 本記事の実務示唆 |
AIエージェントとは
AIエージェントとは、与えられた目標に対して、自分で計画を立て、外部ツールを呼び出し、結果を検証しながら次の行動を選ぶことを反復する自律的なシステムを指す。人間が一手ずつ指示する従来のソフトウェアと違い、ゴールだけを渡せば途中の手順を自分で組み立てて進める点が核心である。ただし「どこからをエージェントと呼ぶか」の線引きは論者やベンダーによって異なり、本記事ではその前提のうえで一般的な区別を整理する。
一言でいうと
一言でいえば、AIエージェントは目標を起点に「計画→実行→検証→反復」というループを自律的に回す仕組みである。LLMが状況を判断し、必要に応じて検索やファイル操作などのツールを使い、得られた結果を踏まえて次の一手を決め直す。この整理は Anthropic の「Building effective agents」を主軸に、Google・Microsoftの仕様や学術研究を含む複数のソースで裏取りしたものである。
ワークフロー型と自律型の違い
両者はともに LLM とツールを組み合わせるが、制御の主体が異なる。ワークフロー型は、あらかじめ人が定義したコードのパスに沿って LLM やツールを順番に編成する方式である。一方で自律型(自律エージェント型)は、どのツールをいつ使い、いつ終えるかを LLM 自身が動的に判断する。Anthropic はこの両者を総称して「エージェント的システム(agentic systems)」と呼び、ワークフローとエージェントを区別している(出典: Anthropic「Building effective agents」)。なお Google の Agent Development Kit のように、エージェントを役割分担で組み合わせるマルチエージェント構成を軸に整理する立場もあり、分類の切り口は提供者ごとに幅がある。
チャットボット・RAGとの違い
一般的な区別として、チャットボットは質問に答えて次の入力を待つ受動的な仕組みであるのに対し、AIエージェントはファイルを読む・コマンドを実行するといった行動を自ら起こし、課題を解き進める能動的な仕組みである。RAG(検索拡張生成)は、外部の知識を検索して回答に付与する「拡張されたLLM」の一機能であり、それ自体がエージェントなのではなく、エージェントを構成する部品の一つと位置づけられる。もっとも、これらの境界は論者によって揺れがあるため、ここでは目安としての区別にとどめる。RAG自体の定義や検索→生成の4ステップ、ファインチューニングとの違いは、RAG(検索拡張生成)の仕組みで詳しく解説している。
仕組み(どう動くのか)
AIエージェントの中核は、検索・ツール実行・記憶の3機能で拡張された大規模言語モデル(LLM)である。素のLLMは入力に対して一度だけ応答を返すが、エージェントは「計画→実行→検証→反復」というループ(計画を立て、ツールを実行し、結果を自己評価して次の手を決める)を、停止条件を満たすまで繰り返す。重要なのは、この性能を決めるのが投入トークン量ではなく、環境から返ってくるフィードバックの質だという点だ。以下、その動作原理を5つの観点で分解する。
中核は拡張されたLLM
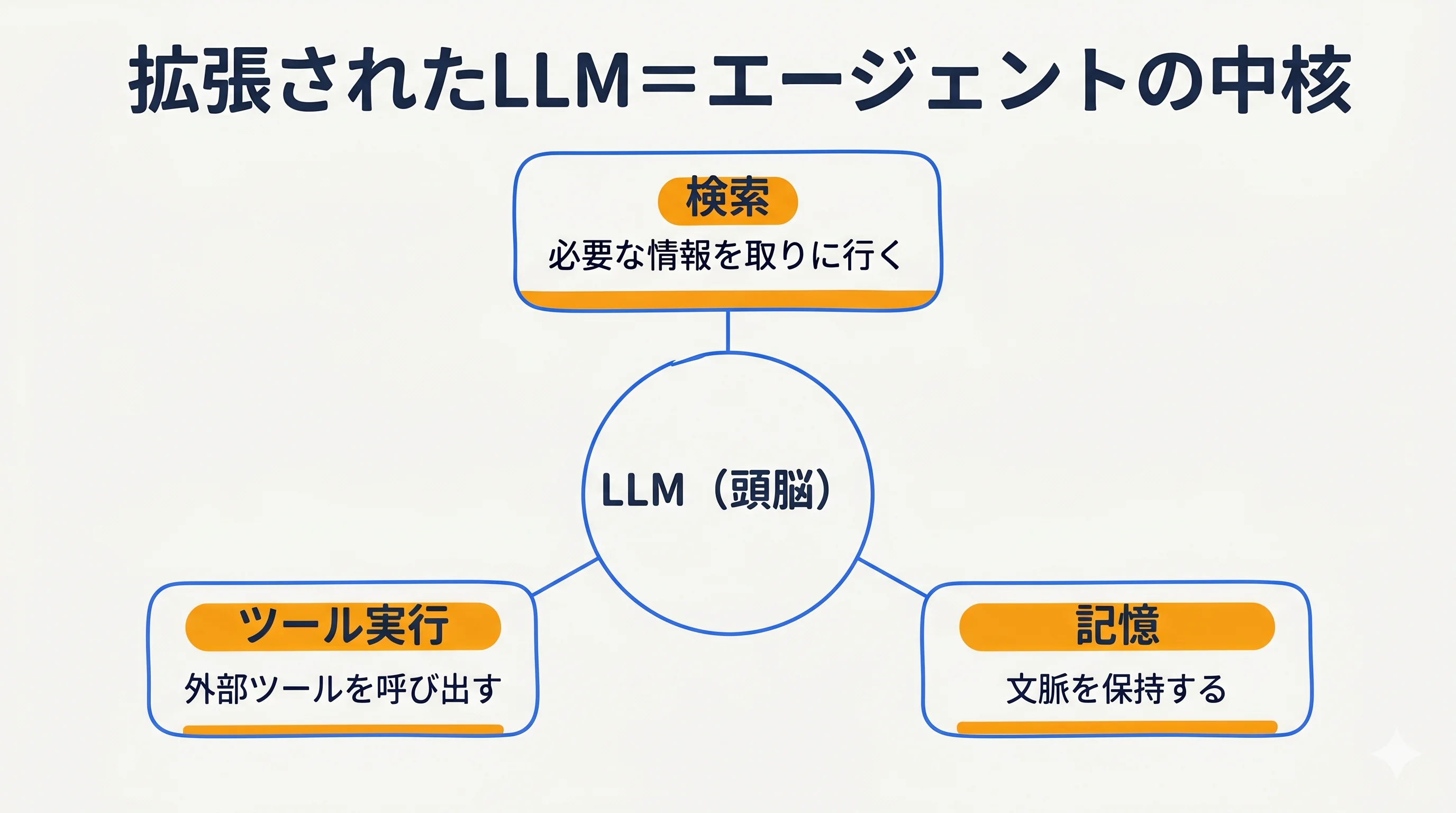
エージェントの判断はLLM自身が担う。どんな検索クエリを投げるか、どのツールを呼び出すか、得た情報のうち何を記憶として保持するか——これらをモデルが文脈に応じて決める。外部の固定ルールがエージェントを動かしているのではなく、LLMが検索・ツール・記憶という拡張機能を能動的に使い分けている点が、従来の自動化スクリプトとの決定的な違いである(出典: Anthropic「Building effective agents」)。
計画→実行→検証→反復のループ
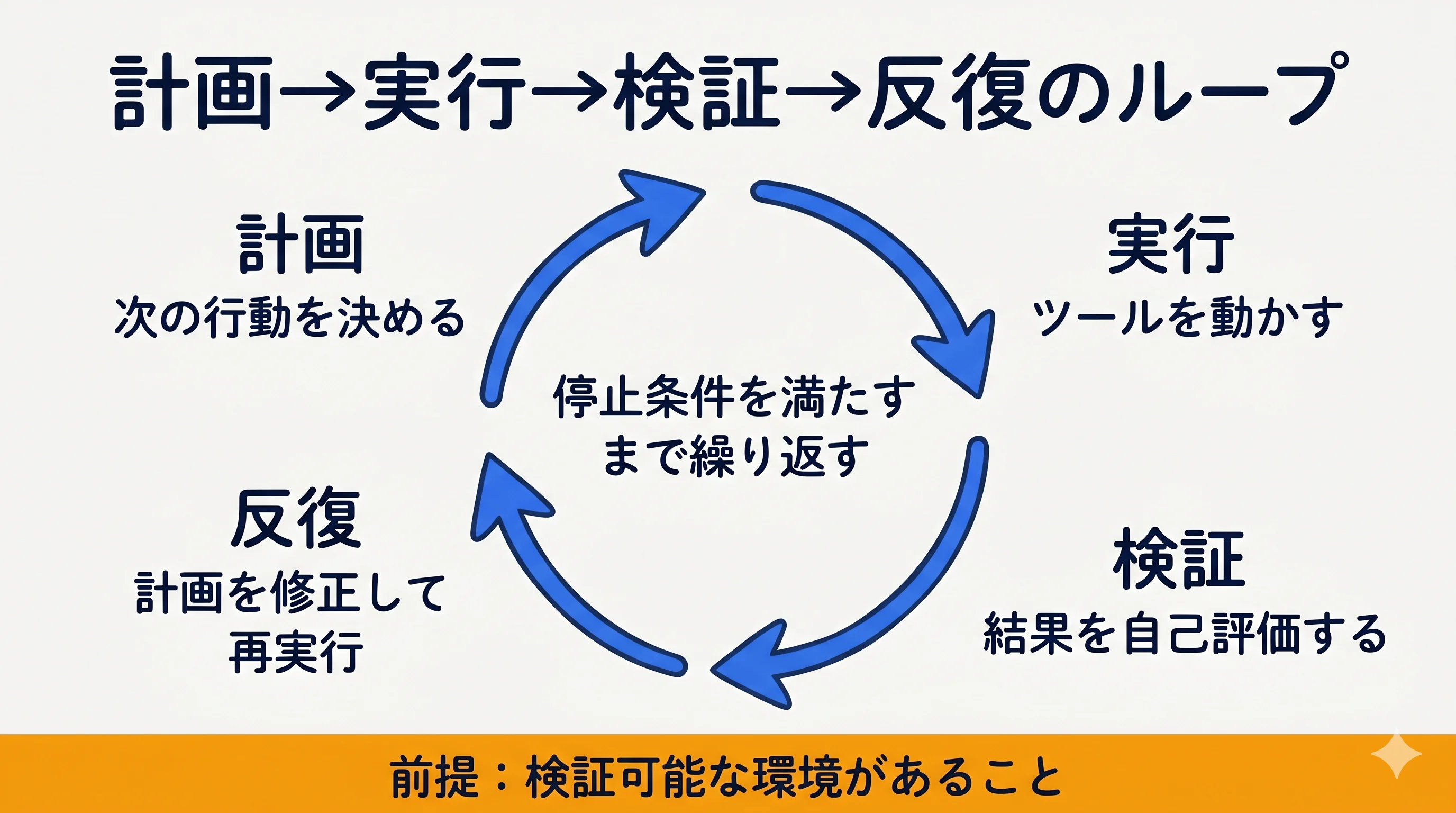
エージェントは、計画を立て、ツールを実行し、その結果を環境からのフィードバックで自己評価し、必要なら計画を修正して再実行する。このループが自分で閉じるかどうかは、検証可能な環境が用意されているかにかかっている。たとえばコード生成なら、テスト・ビルド・lintといった検証チェックが「成功/失敗」を機械的に返すため、エージェントは外部の判断を待たずにループを完結できる。明確な停止条件と検証可能な環境の2つが、自律的な反復が成立する前提となる。
計画の質が成否を分ける
計画立案はエージェントの中核能力だが、同じタスクでも計画の表現形式や計画立案に使うモデルによって、成功率と頑健性が有意に変わることが報告されている(出典: arXiv:2605.29927)。この知見は製品実装にも表れており、計画を立てるフェーズと実行するフェーズを分離する設計(計画専用モード)が採用されている。計画と実行を分けることで、誤った方針のまま実行が突き進むのを防ぎ、計画段階で軌道修正できる利点がある。
外部接続の標準プロトコル
エージェントが外部ツールやデータ源に接続する際の標準として、MCP(Model Context Protocol)が広く使われている。MCPはJSON-RPC 2.0をベースに、ホスト・クライアント・サーバーの3者構成で通信する。ホスト側のアプリケーションがクライアントを通じて各サーバー(ファイル、データベース、外部APIなどを提供する)と接続し、ツール呼び出しや情報取得を行う仕組みだ(出典: MCP仕様 2025-11-25・参照 2026-05-30 時点)。具体的な接続手順や設定例は、Claude CodeとMCPの連携手順で詳しく扱う。
なぜ賢く動くのか
エージェントの性能は、消費トークン量やツール呼び出し回数では説明できない。決め手は、実行環境(harness)から返るフィードバックの質である。これを定量的に示した研究では、実行環境が生む有効なフィードバックの量(EFC)とタスク成功の相関は決定係数(R²)で0.94〜0.99に達した(出典: arXiv:2605.29682)。一方、素のトークン消費量やツール呼び出し回数と成功の相関は、同じ指標で0.33〜0.42にとどまった(出典: arXiv:2605.29682)。つまり「より多く考えさせる」よりも「より良いフィードバックを返す環境を整える」ほうが、エージェントを賢く動かす近道だと言える。
種類・分類
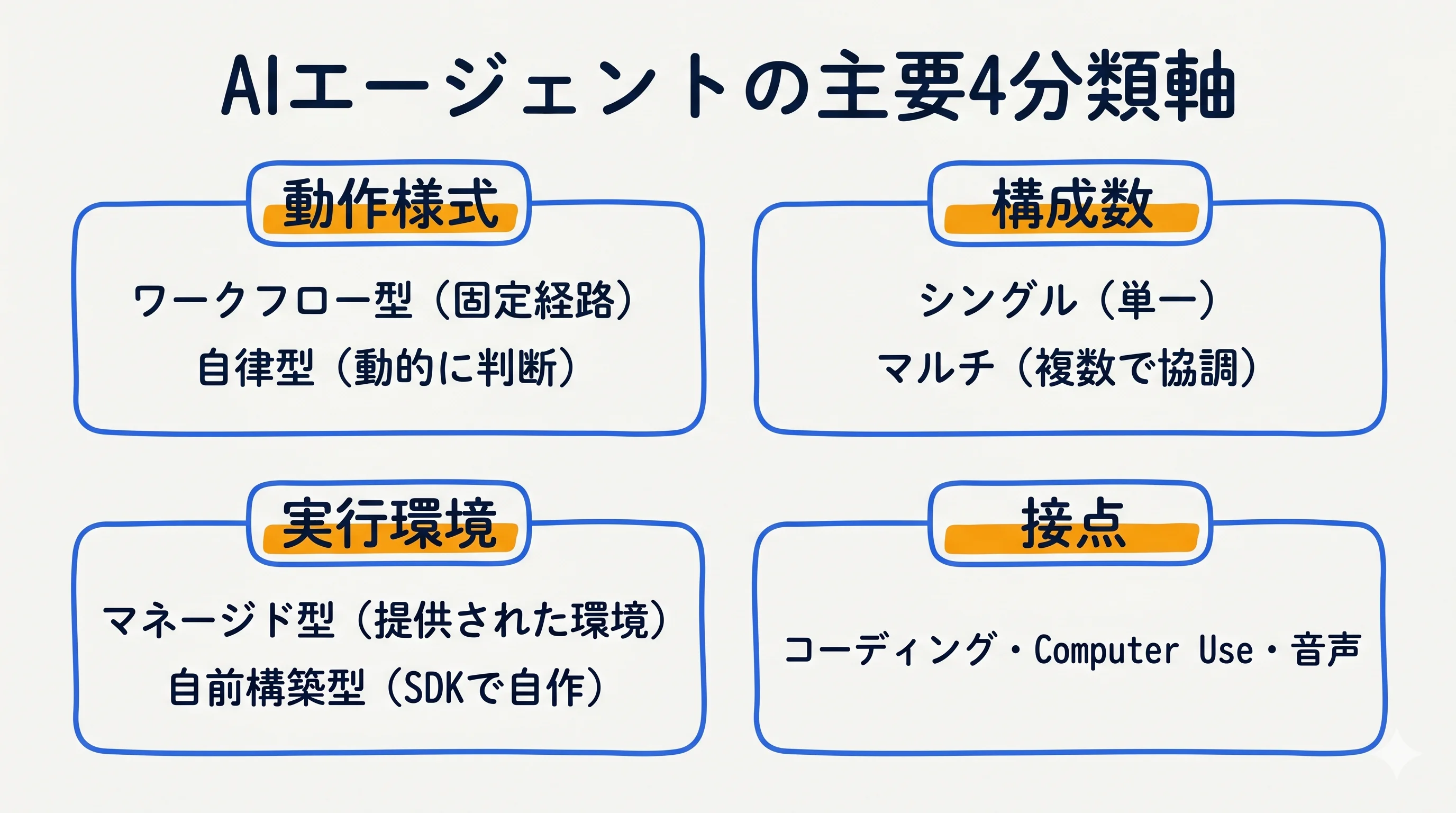
AIエージェントは単一の基準で割り切れず、見る角度によって分類が変わる。実務でよく使われるのは、自律度・動作様式・構成数・実行環境・接点(インターフェース)・起動契機・ドメイン特化という7つの軸である。ただし「どの軸を主とするか」「どこからをエージェントと呼ぶか」は論者やベンダーによって異なり、業界で統一された分類はまだ存在しない。まずは全体像を一覧で押さえ、その後に実務で重要な4つの軸を掘り下げる。
| 分類軸 | 説明 | 代表例 | 主な出典 |
|---|---|---|---|
| 自律度(ワークフロー型と自律型) | 事前に定義された処理パスに沿うか、LLMが動的に判断するか | ワークフロー(routing等)/自律型 | Anthropic「Building effective agents」 |
| 動作様式(5つのワークフローパターン) | prompt chaining/routing/parallelization/orchestrator-workers/evaluator-optimizer | 各パターン | Anthropic「Building effective agents」 |
| 構成数(シングルとマルチ) | 単一エージェントか、複数が協調するか | CrewAI、AutoGen、LangGraph | Anthropic/各OSS |
| 実行環境(マネージドと自前構築) | ベンダーがホストする隔離環境か、自作のharnessか | マネージド型エージェント/自前SDK | Anthropic公表 |
| 接点(インターフェース) | コーディング/Computer Use/音声/起動契機 | コーディングエージェント、Computer Use | Anthropic公表 |
| 起動契機(指示待ちとプロアクティブ) | 人間が起動するか、自発的に動き出すか | スケジュール起動エージェント | 一般分類 |
| ドメイン特化(汎用と業務特化) | 汎用アシスタントか、特定業務向けか | 業種特化エージェント | 一般分類 |
動作様式で分ける(ワークフロー型と自律型)
動作様式の軸では、まず処理の流れが固定された「ワークフロー型」と、LLMが次の行動を動的に決める「自律型」を区別する。Anthropic は「Building effective agents」で、ワークフロー型を次の5パターンに整理している。prompt chaining は1つのタスクを逐次的なステップに分解し、前の出力を次の入力につなぐ。routing は入力をまず分類し、適した処理経路へ振り分ける。parallelization は独立した処理を並列に実行して後で統合する。orchestrator-workers は中央のオーケストレーターがタスクを分割し、複数のワーカーへ委任する。evaluator-optimizer は生成役と評価役を分け、評価とやり直しを反復して品質を高める。これら5つは「処理経路があらかじめ決まっている」点が共通する。
対して自律型エージェントは、こうした経路を固定せず、LLM自身が状況を見て使うツールや次の一手を選ぶ。固定経路で十分なタスクはワークフロー型のほうが予測可能で安価になりやすく、判断の余地が大きいタスクほど自律型が向く、という使い分けになる。実装に使う具体的な道具立ては、AIエージェントフレームワークの比較で整理している。
単体かチームか(シングルとマルチ)
構成数の軸では、1つのエージェントが完結させる「シングルエージェント」と、複数のエージェントが役割を分担して協調する「マルチエージェント」に分かれる。マルチでは、タスクをどう編成し、どう並列化し、どう協調させるかというオーケストレーションが核心になる。代表的なのは役割ベースの協調で、CrewAI のように「リサーチ担当」「執筆担当」のような役割を与えたエージェント同士を連携させる方式がある。ただしエージェントを増やすほど、全体としての出力が食い違う非整合のリスクが高まる。実際、あるマルチエージェント研究では、組み合わせの33〜94%で全体としての非整合が生じたと報告されている(arXiv:2605.30335)。この度合いの背景は後段の限界セクションでも詳しく扱う。
動く場所で分ける(マネージドと自前構築)
実行環境の軸では、エージェントがどこで動くかで分類する。マネージド型は、ベンダーがホストする隔離されたLinuxサンドボックス上でエージェントが動き、計画立案・コード実行・ファイル管理・Web閲覧といった一連の作業をその環境内で完結させる(出典: Anthropic公表)。利用者はインフラを用意せず、提供された環境をそのまま使える。一方の自前構築型は、SDKや独自のharness(エージェントを動かす足場となる仕組み)を組み合わせて自分で構築する。柔軟性は高いが、ツール接続・サンドボックス・エラー処理などを自前で設計・運用する必要がある。手軽さを取るならマネージド型、制御と組み込みの自由度を取るなら自前構築型、という棲み分けになる。
接点で分ける(インターフェース)
接点の軸は、エージェントが人間や外部とどう接するかによる分類である。コーディング向けは、コードの生成・編集・デバッグ・テスト実行を担うエージェントで、開発作業そのものを自動化する。具体的なツール選定の観点はAIコーディングツールの比較・選び方で整理している。Computer Use 型は、画面を見てマウスやキーボードを操作する、いわばGUIを直接扱うエージェントで、専用APIのないアプリにも介在できる(出典: Anthropic公表)。音声型は、音声を直接入出力する speech-to-speech 方式で、テキストを介さない対話を実現する。さらに起動契機でも分かれ、人間の指示を待ってから動く「指示待ち型」と、条件やスケジュールに応じて自発的に動き出す「プロアクティブ型」がある。同じエージェントでも、どの接点を持つかで使いどころが大きく変わる。
できること・できないこと
AIエージェントの能力と限界を語るとき、両者は出所の性質が異なる。「できること」の根拠は、各ベンダーが公表するプロダクト仕様であり、独立した第三者の検証ではない。一方「できないこと・限界」の根拠は、特定の製品を売る立場にない独立した一次研究(arXiv の査読前論文)である。本記事はこの出所の非対称をそのまま明示したうえで、両者を対等に並べる。期待を語るベンダーの声と、限界を測る研究者の声を、混ぜずに分けて扱うことが中立な現在地の把握につながる。
できること(ベンダー公表のプロダクト仕様)
下表は、各社が公表しているプロダクト仕様に基づく「できること」7項目である。表の内容はいずれもベンダー公表のプロダクト仕様であり、独立検証ではない点に注意してほしい。とくにベンチマーク数値は提供元が自社で公表した値で、第三者による検証は行われていない。あくまで「各社がこう公表している」という事実記述として読む。
| できること | 内容 | 出所(ベンダー公表のプロダクト仕様・独立検証ではない) |
|---|---|---|
| 計画・ツール選択・反復 | 事前にハードコードできない open-ended な課題に対し、自分で計画を立て、使うツールを選び、反復して進める | Anthropic「Building effective agents」/Google Gemini 3.5 |
| PC・ブラウザ・ターミナル操作 | GUI やコマンドラインを自律操作する(Computer Use) | Google Gemini API changelog/Anthropic「Claude Opus 4.8 News」 |
| 長期タスクの継続 | 数日〜数週かかる long-horizon なタスクを継続実行する | Google Gemini 3.5/Anthropic Claude Code docs |
| 外部ツール・データへの接続 | MCP 等の標準プロトコルでファイル操作・Git 操作・Web 検索・コード実行などを行う | MCP 仕様/Microsoft Agent Framework |
| 複数エージェントの編成 | 複数エージェントを編成・並列・協調させ大規模な問題に対応する | Anthropic「Claude Opus 4.8 News」/CrewAI/Google ADK |
| 検証ループの自己完結 | テスト・ビルド・lint などの検証チェックを与えると合格まで自己反復し、ループを自分で閉じる | Anthropic Claude Code docs |
| 自律性と安全制御の両立 | 人間の承認を介在させたり、危険コマンドだけをブロックしたりして自律性と安全制御を両立する | Anthropic Claude Code releases/Agno |
ベンチマーク数値も同じ枠組みで扱う。たとえば Anthropic は、エージェント系ベンチマークの Online-Mind2Web で 84% を公表し、前世代(Claude Opus 4.7)や他社モデルを上回ると説明している。一方、しばしば引用される OSWorld-Verified の 82.3% は、Anthropic が評価方法を更新したうえで示した Opus 4.7 のスコアであり、最新モデルそのものの数値ではない点に注意が要る。いずれもベンダーの自社公表値で第三者検証はなく、Google なども同種の自社公表値を出しているが、計測条件が各社で異なるため横断的な順位比較は本記事の射程外とする。数値を能力の保証として読むのではなく、「どのベンダーが・どのモデルで・どの水準を主張しているか」を区別して受け取るのが妥当である(出典: Anthropic「Claude Opus 4.8 News」2026-05-28・ベンダー自社公表値、第三者検証なし・参照 2026-05-30 時点)。
できないこと・限界(独立した一次研究にもとづく)
下表は独立した一次研究が報告する限界である。出所の信頼性を保つため、各限界には単一の一次研究を1対1で紐付ける。複数の論文を束ねて1つの数字に見せることはしない。
| 限界 | 内容 | 単一の一次研究 |
|---|---|---|
| 冗長な手順を自動検出できない | 目的に無関係な冗長ステップを頻繁に踏むうえ、その冗長性を自動で見抜くのも難しく、最良手法でもスコアは24.88%にとどまる | arXiv:2605.29893 |
| 十分でも止まれない | 検索ツールを使う際に自己認識が弱く、すでに十分な情報が集まっても探索を止められない(over-search) | arXiv:2605.29796 |
| 長期記憶が劣化する | 長期タスクで過去を要約して保持するが、再帰的な要約により重要情報が失われ推論が劣化する | arXiv:2605.30159 |
| 全体で判断が矛盾する | マルチエージェント構成では各部品が個別には正しくても全体で矛盾した判断をしうる(テストで33〜94%が非整合) | arXiv:2605.30335 |
| 計画の質がばらつく | 計画は中核能力だが、計画の表現形式や立案するモデルによって成功率・頑健性が有意に変わり、質が安定しない | arXiv:2605.29927 |
| ツール権限のリスク | MCP はプロトコル上セキュリティを強制せず、ツールは任意コード実行扱いでユーザー同意が必須になる(権限設計を誤ると実害につながる) | MCP 仕様 2025-11-25 |
| 検証環境がないと暴走する | 各ステップで環境からの正解情報がないと誤差が累積し、検証可能な環境と停止条件を欠くと暴走しうる。単純な定型処理にはオーバースペックで遅延とコストが増える | Anthropic「Building effective agents」 |
数値は1値1出典で読むのが要点である。冗長行動の自動検出が最良でも24.88%という値は arXiv:2605.29893 単独の報告であり、マルチエージェントの非整合が33〜94%という値は arXiv:2605.30335 単独の報告である。別々の研究の数字を1つの根拠に束ねないことが、限界の正確な把握には欠かせない。なお MCP 仕様は更新が続くため、上表の権限リスクは安定版 2025-11-25 の記述にもとづく(参照 2026-05-30 時点)。
限界をどう囲うか
限界があること自体は導入を止める理由にならない。重要なのは、限界を運用設計で囲い込めるかどうかである。実際の安全制御は次の4つの組み合わせで成り立つ。第一に、人間の承認を要所に挟む human-in-the-loop。第二に、危険なコマンドだけを分類器でブロックし、それ以外は承認なしで自律実行させる auto mode。第三に、操作の前に人が可否を判断する承認ワークフロー。第四に、プロンプト任せにせず、アプリケーション層で決定論的に統制する仕組みである。
ここでカギになるのは、安全をモデルの賢さに期待しないという発想だ。独立研究はマルチエージェントが全体で矛盾しうると報告しており(arXiv:2605.30335)、プロンプトレベルの注意書きだけでは制御しきれない。誰が・いつ・どのツールに・どの権限を与え・どこで人が止めるかを、アプリ層の決定論的なルールとして外側から固定する設計が現実的である。導入現場で実際にどんな囲い方が失敗するのか、その具体例は社内AI導入でよくある失敗7つで扱う。
導入の全体像(中小・中堅企業の現実)
中小・中堅企業がAIエージェントを導入するなら、最初から自律エージェントを狙わず、定型業務をワークフロー型から入るのが現実的だ。導入できるかどうかの第一基準は、性能の高さやモデルの新しさではなく、合否を判定できる検証手段・与える権限の範囲・処理を止める停止条件・人が承認する地点を社内に用意できるか、の4点に尽きる。AIエージェントの中核は計画→実行→検証→反復のループであり、各ステップで環境からの正解(ground truth)が得られないと精度が落ち誤差が累積する(出典: Anthropic「Building effective agents」)。この前提を踏まえると、人員が少なくフルタイムで監視できない中小ほど、運用設計で限界を囲い込むことが導入成否を分ける。汎用的な解説記事の多くが自律エージェント礼賛に寄るのに対し、ここでは中小・中堅の現実に即した4つの判断軸を示す。
まずワークフロー型から始める
業務が定型であるほどワークフロー型で十分であり、予測可能・低コスト・監査しやすいという中小の現実によく合う。AIエージェントは事前にコードパスを決められない手順自由(open-ended)な課題に強みがある一方、手順を事前に決められる定型処理にはオーバースペックで、遅延とコストが増える(出典: Anthropic「Building effective agents」)。請求書の仕分け、問い合わせの一次振り分け、定型レポートの下書きといった手順が決まった業務なら、入力を分類して専門処理へ振り分けるルーティング型のワークフローで予測可能に回せる。
導入可否を判断する第一基準は、その業務に合否判定(ground truth=正解)となる検証手段を社内に用意できるかである。出力が正しいかを誰がどう確認するかを決められない業務は、自律実行に任せると誤差が累積し暴走や無限ループのリスクが高まる。自律エージェント礼賛に流されず、検証できる定型業務から始めるのが安全な入口になる。
限界を人手レビューと承認で囲う
AIエージェントには、十分な情報が集まっても止まれない、目的に無関係な冗長行動を取る、長期タスクで記憶が劣化する、複数エージェント構成では全体の判断が矛盾する、といった一次研究で確認された限界がある。冗長な手順は自動検出自体が難しく最良手法でもスコアは24.88%(arXiv:2605.29893)、複数エージェント構成ではテストの33〜94%が全体で非整合になる(arXiv:2605.30335)。これらは設定の調整だけでは消えないため、運用側で人手レビューと承認の地点を設けて囲い込む(human-in-the-loop)のが現実的な対処になる。
フルタイムで監視できない中小・中堅では、すべてを人が見張るのではなく、危険な操作だけをブロックし、完了報告を人が最終確認する運用が、丸投げの自律実行より安全で低コストだ。実際にAIエージェントの製品では、別の分類器が実行コマンドを事前審査し、スコープ逸脱や危険な操作だけを止めて、それ以外は承認なしに自律実行する仕組みが提供されている(出典: Anthropic Claude Code releases・参照 2026-05-30 時点)。停止条件と承認点を業務フローに組み込むことが、少人数でも事故を抑える鍵になる。失敗の具体例は社内AI導入でよくある失敗7つで扱う。
ツール権限は運用ルールで縛る
外部接続の標準であるMCP(Model Context Protocol)は、プロトコル上はセキュリティを強制しない。MCPの仕様自体が、ツールは任意コード実行として扱われること、ツールを呼び出す前に必ずユーザーの明示的な同意(consent)が前提であることを明記している(出典: MCP仕様 2025-11-25・参照 2026-05-30 時点)。つまり、どのツールに何を許可するかは仕様任せにできず、導入する側が決める必要がある。
業務ファイルや顧客情報を扱う中小・中堅では、どのツールにファイル読み書き・外部送信・コマンド実行のどこまでを与えるかを、運用ルールとして文書で規定することが欠かせない。最小権限で開始し、必要に応じて段階的に広げる。アプリ層での決定論的な統制(ポリシー強制・サンドボックス・承認フロー)が必要であることは、プラットフォーム提供側のガバナンス資料でも繰り返し示されている(出典: Microsoft agent-governance-toolkit・参照 2026-05-30 時点)。権限設計を誤ると、自律実行がそのまま情報漏洩や誤操作の実害につながる。
具体的な導入手順は5ステップ記事へ
ここまでで示したチェック観点は、検証手段(合否判定を社内に用意できるか)・権限範囲(どのツールに何を許可するか)・停止条件(どこで処理を止めるか)・承認点(誰がいつ最終確認するか)の4つである。この4観点を満たせるかが、導入してよい業務かどうかの判断材料になる。具体的にどの順番で社内へ展開するかという手順は、社内AI導入を進める5ステップで段階を追って解説している。また、導入の効果は導入を決めた時点から基準値を記録しておかないと後から金額換算できない。ROIの計算式とKPI設計はAIエージェントのROI・効果測定で解説している。
導入してよいと判断した後、AIエージェントが実際にどう動くのか、本当に期待どおりに動作するのかを確かめたい場合は、話題のAIエージェントを実務で検証してみたで実際の挙動を確認できる。導入前に挙動を検証しておくことが、検証手段を社内に持つ第一歩にもなる。
自社で何から始めるかを具体的に知りたい場合は、社内AI導入を進める5ステップを参照してください。
よくある質問
- Q. チャットボットとの違いは?
- チャットボットは入力された質問に1回ずつ答えるだけで、会話が終われば何も残りません。AIエージェントは目標を受け取ると、自分でやることを分解し、ツールを呼び出し、結果を見てやり直す、というループを回します。つまり「答えるだけ」がチャットボットで、「目標達成まで動き続ける」のがエージェントだと考えると分かりやすいです。設計の枠組みとしては、Anthropicも「ワークフロー」と「エージェント」を区別しています(出典: Anthropic「Building effective agents」)。
- Q. RAGとの違いは?
- RAGは社内文書などを検索して、その内容を踏まえて回答を生成する仕組みで、あくまで「正確に答えるための材料集め」が役割です。AIエージェントはRAGを部品の1つとして使えますが、それだけでは終わりません。検索した内容をもとに次の行動を決め、別のツールを動かし、必要なら何度も検索し直します。RAGは知識を補う技術、エージェントは行動を組み立てる主体、という関係です。
- Q. ワークフロー型と自律型はどちらを選ぶべき?
- 手順がだいたい決まっている業務なら、まずワークフロー型が無難です。あらかじめ決めた流れに沿って動くので結果が予測しやすく、検証も運用もしやすいからです。一方で、状況によって取るべき手順が変わる業務には自律型が向きますが、何をするか事前に固定できないぶん、想定外の動きや失敗も起こりやすくなります。迷ったら「手順を固定できるか」を基準に、固定できるならワークフロー型から始めるのが安全です。
- Q. 中小企業でも使える?
- 使えます。クラウドで提供されるサービスが増えたため、自前で大規模なインフラを持たなくても、業務の一部から小さく試せます。ポイントは、いきなり全自動を狙わず、定型作業や下調べなど失敗しても影響が小さい範囲から導入することです。導入の進め方は社内AI導入を進める5ステップで具体的に解説しています。
- Q. AIエージェントにできないことは?
- 現在のAIエージェントは、長い手順を最後まで安定してこなすのが苦手です。たとえば無駄な行動を取る冗長行動を自動検出する手法でも最良で24.88%にとどまり(出典: arXiv:2605.29893)、複数エージェントが連携する構成では33〜94%が全体で非整合になります(出典: arXiv:2605.30335)。詳しい数値と背景は本文「できないこと・限界」で扱っています。今のエージェントは「人の確認なしで全部任せる」段階ではなく、要所で人がチェックする前提で使うのが現実的です。
出典・参考資料
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.