AIコーディングエージェントのチーム導入ガイド【2026】進め方・ガバナンス・効果測定
一次ソース検証型AIメディア編集部 ・ 監修: 依田 尚人
目次
- 結論:導入ステップ早見+つまずきの真因
- なぜチーム導入は個人利用と違って難しいか
- 個人習熟とチーム展開の断絶
- ガバナンス・効果説明責任という新たな壁
- 導入ステップ:PoC→Pilot→全社展開のゲート判定
- ステップ1 PoC(小さく検証・選定はツール比較へ)
- ステップ2 Pilot(限定チームでゲート判定)
- ステップ3 全社展開(合格条件と撤退基準)
- ガバナンス:権限・レビュー・学習除外
- リポジトリ権限とコードレビュー必須化
- 学習除外・監査ログ・IP(組織ポリシーで敷く)
- 効果測定:DORA/SPACE をAIコーディングに当てる
- DORA(4→5指標)でデリバリーを測る
- SPACE(5次元)で開発者体験を測る
- ツール別の管理機能
- まとめ
ツールは選んだ(または絞れた)が、開発チーム全員に AI コーディングエージェントを「どう入れて、どう統制し、効果をどう説明するか」が分からない。本記事は2026年6月23日時点の各社公式情報に基づき、特定ツールを推さず、チーム導入の進め方を中立に整理する。
チーム導入は「ツールを配るだけ」では定着しない。PoC(小さく検証)→ Pilot(限定チームでゲート判定)→ 全社展開(合格条件と撤退基準を明示) の3段階で進め、各段階で「リポジトリ権限・コードレビュー必須化・学習除外」のガバナンスを敷き、効果は DORA/SPACE の枠組みで測るのが基本である。決め手はツールの優劣ではなく「段階判定とガバナンスを最初に設計したか」である。
つまずきの真因はここにある。個人で使えること(習熟)と、チームで安全に・測れる形で回ること(展開)は別物である。後者を設計せずに配ると、レビューの形骸化・学習除外の漏れ・効果が説明できない、の3つで止まる。なお当社(YDAIコンサルティング AI編集部)は Claude 系ツールのヘビーユーザーであり、Anthropic のエコシステムで開発受託も行う立場にある。そのうえで、本記事はどのツールも勝たせず中立に整理する。ツール選定そのものは「AIコーディングツール比較(4ツール総合)」を参照してほしい。
結論:導入ステップ早見+つまずきの真因
導入は「配布」ではなく「段階判定+ガバナンス+効果測定の設計」である。ツール選定は前提として済ませ、本記事は「入れた後の組織展開」を扱う。下表は段階導入の枠組みと公式仕様を横断統合した本記事独自の早見である。
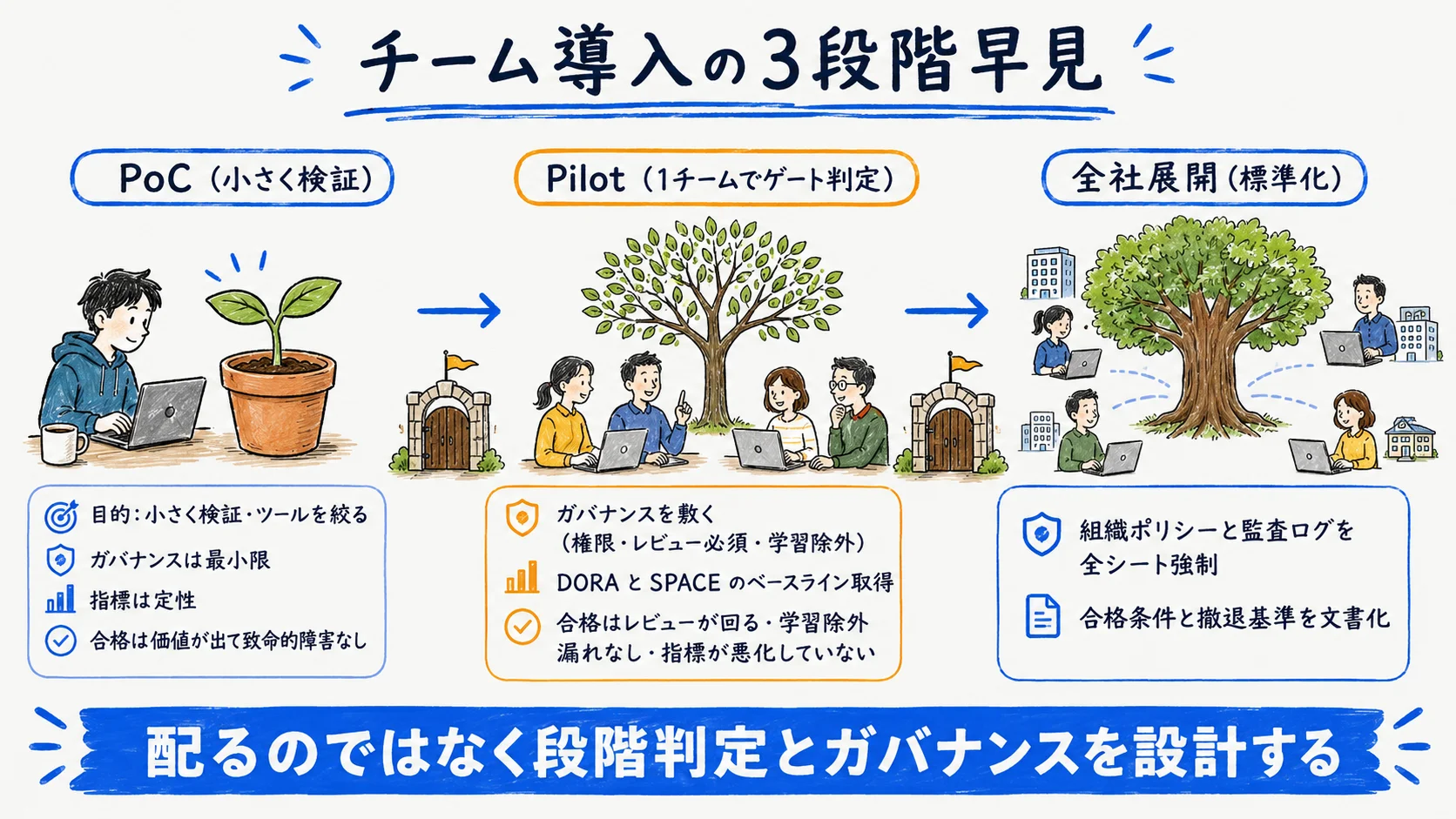
| 段階 | 主目的 | 敷くガバナンス | 取る指標 | 次へ進む合格条件 |
|---|---|---|---|---|
| PoC | 小さく検証・ツールを絞る | 最小限(実コードでの安全確認) | 定性(実タスクで価値・致命的障害なし) | 価値が出た/致命的障害なし |
| Pilot | 1チームで本番近い運用 | 権限最小化・レビュー必須化・学習除外 | DORA/SPACE のベースライン取得 | レビューが回る/学習除外漏れなし/指標が悪化していない |
| 全社展開 | 対象拡大・標準化 | 組織ポリシー・監査ログを全シート強制 | DORA/SPACE の継続観測 | 合格条件と撤退基準を文書化済み |
各段階で何を決め、どう測るかを以降で順に解説する。
なぜチーム導入は個人利用と違って難しいか
「使える人がいる=定着」ではない。チーム導入には個人利用にない壁がある。順に見ていく。
個人習熟とチーム展開の断絶
個人が使える状態(プロンプトやツール操作の習熟)と、チームで安全に回る状態(権限・レビュー・学習除外・標準化)は、別の課題である。個人の習熟は本記事の対象外とし、ここでは組織展開だけを扱う。個人の使い方や非エンジニアの活用は「非エンジニアのClaude Code活用」に委ねる。
重要なのは、習熟した個人が数人いても、それがそのままチームの定着にはつながらない点だ。展開を設計しないまま配布すると、使う人と使わない人の差が広がり、品質と運用がばらつく。
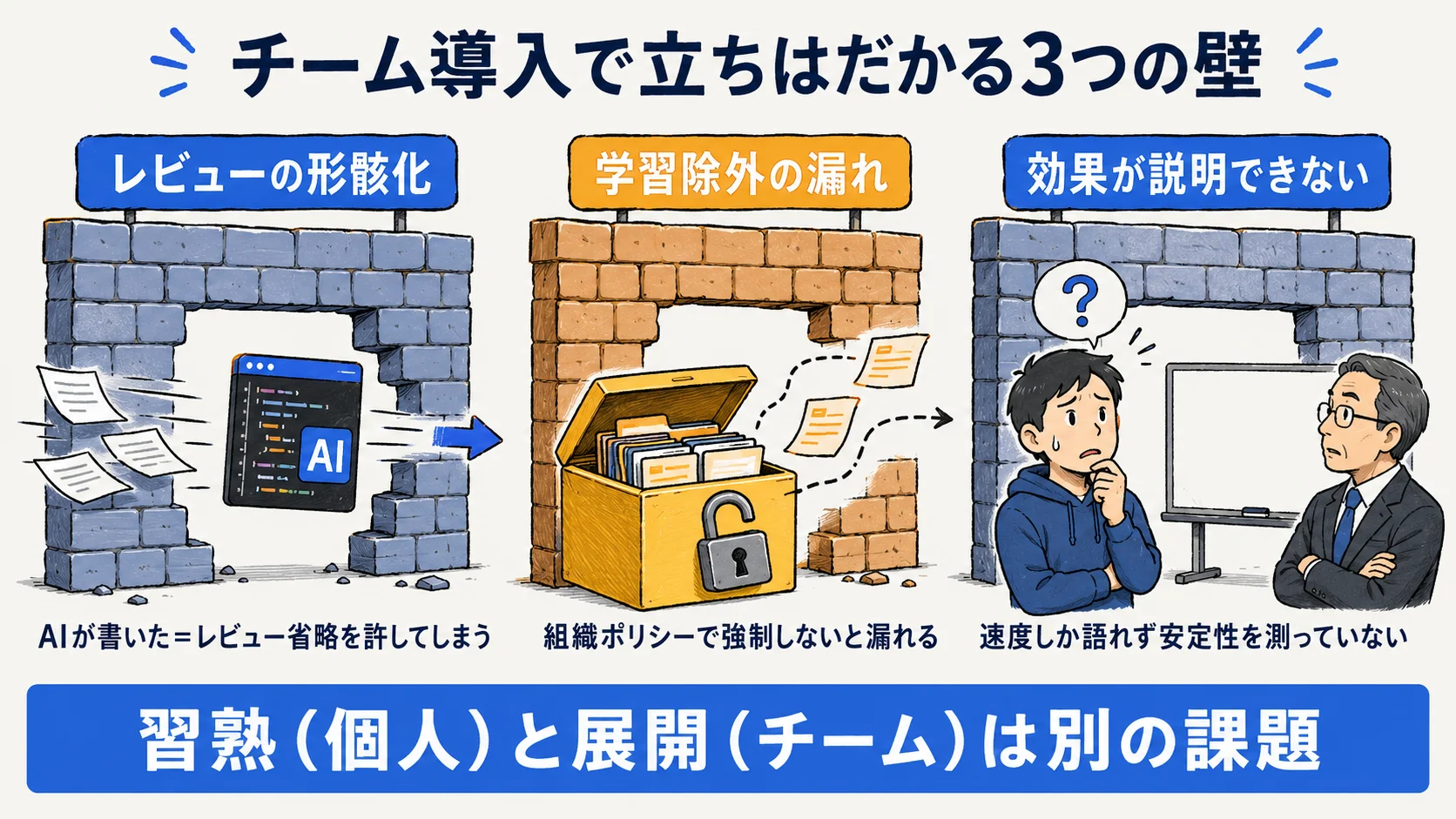
ガバナンス・効果説明責任という新たな壁
チームでは個人利用になかった問題が立ち上がる。未レビューのAI生成コードがマージされる、学習除外の設定漏れ、導入効果を経営に説明できない、の3つである。これがチーム導入特有の難所だ。
この3つの壁は、後段で各個撃破する。レビュー形骸化と学習除外の漏れはガバナンス(後述)で、効果が説明できない問題は効果測定(後述)で対処する。先に壁を認識し、PoC からではなく Pilot の段階で対策を敷くのが定石である。
導入ステップ:PoC→Pilot→全社展開のゲート判定
プレイブックの核は、各段階に「次へ進む合格条件」を置くことだ。順に見ていく。
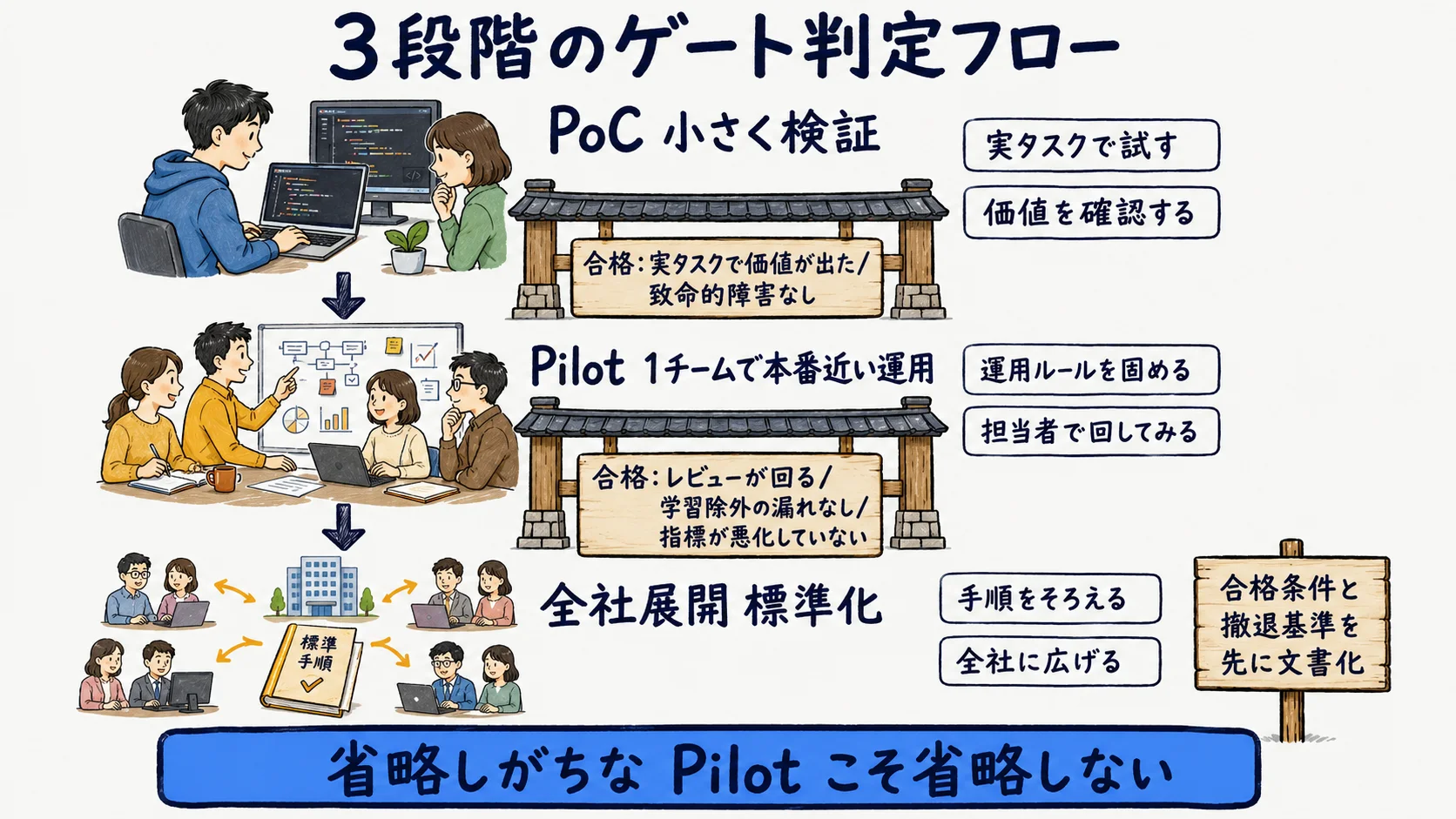
ステップ1 PoC(小さく検証・選定はツール比較へ)
1〜数人で短期間、実コードベースに対して検証する。ここでツールを絞り込むが、選定の各論は「AIコーディングツール比較」に委ね、本記事では繰り返さない。
PoC の合格は数値ではなく定性で確認する。実タスクで価値が出たか、致命的な障害がないか、の2点だ。ここで完璧を求めず、次の Pilot に進めるかどうかだけを判断する。PoC を本番運用へ乗せる工程設計は別記事の範囲とし、本記事では深追いしない。
ステップ2 Pilot(限定チームでゲート判定)
1チーム規模で、本番に近い運用を回す。ここで初めてガバナンス(権限・レビュー必須化・学習除外)を敷き、効果測定(DORA/SPACE)のベースラインを取る。
Pilot のゲート判定は3点で行う。レビュー運用が回るか、学習除外が漏れないか、効果指標が悪化していないか、である。これらが満たせなければ全社展開はしない。撤退するか、条件付きで継続するかを選ぶ。Pilot はチーム導入で最も省略されやすく、最も省略してはいけない段階だ。
ステップ3 全社展開(合格条件と撤退基準)
Pilot 合格後に対象を拡大する。展開時は「合格条件(何が満たされたら広げるか)」と「撤退基準(何が起きたら止める・縮小するか)」を最初に文書化しておく。
シートやライセンスは段階的に増やし、ガバナンス設定(組織ポリシー・監査ログ)を全シートへ展開・強制する。展開を急いで撤退基準を決めずに広げると、問題が起きたときに引き返せなくなる。撤退基準は「導入の失敗」ではなく「健全な歯止め」として最初に置くのが要点だ。
ガバナンス:権限・レビュー・学習除外
チーム導入特有の壁を、組織ポリシーとして敷く。順に見ていく。
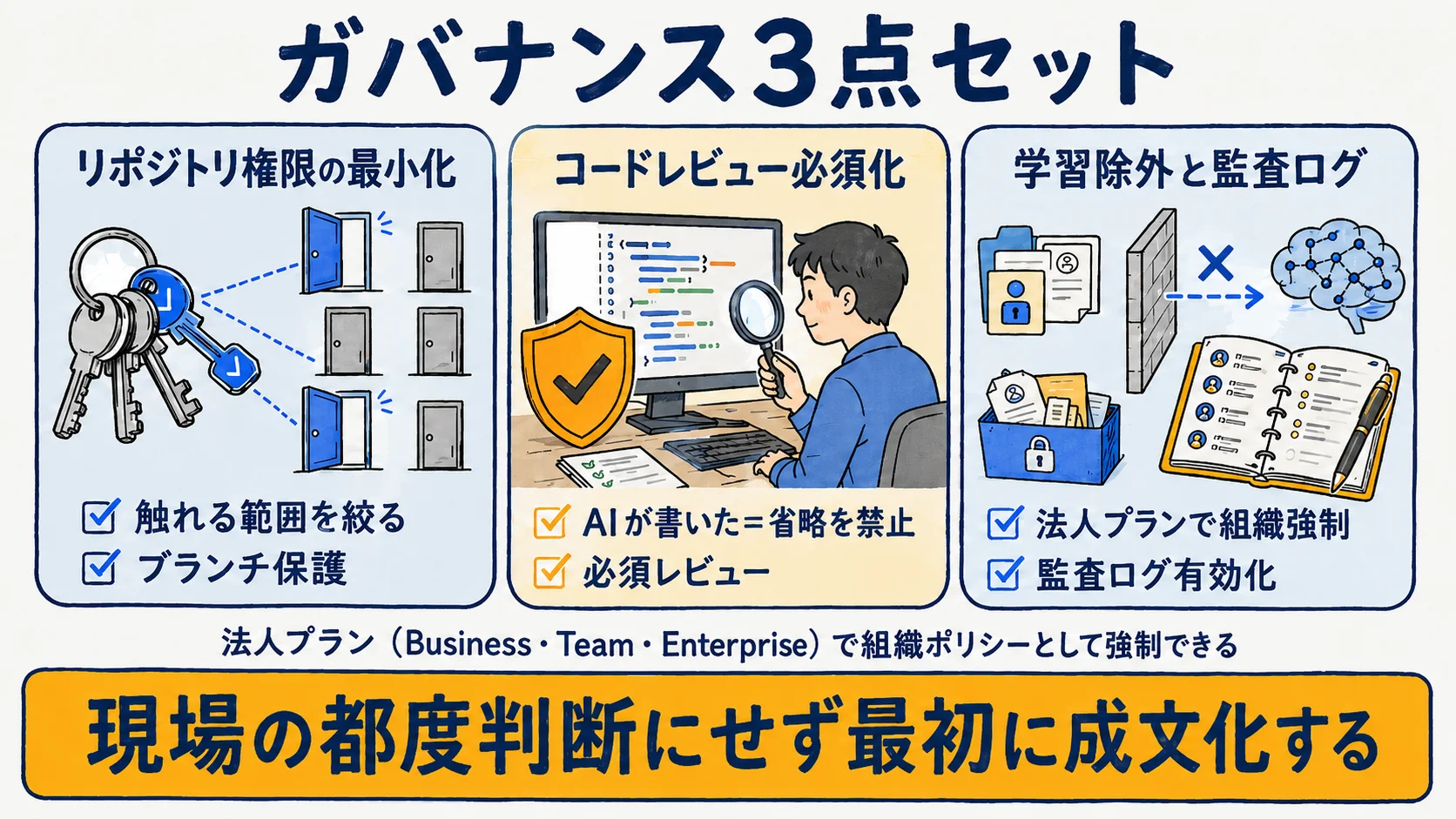
リポジトリ権限とコードレビュー必須化
AIが触れるリポジトリやブランチの範囲は、最小権限で設計する。そのうえで、AI生成コードも人のレビューを必須化する(ブランチ保護・必須レビュー)。「AIが書いた=レビュー省略」を組織ルールで明確に禁じることが要点だ。
権限の技術的な落とし穴や設計の詳細は「エージェント権限の落とし穴」に委ねる。本記事で扱うのは、それを組織ポリシーとしてどう敷くかである。権限とレビューを最初に成文化しておかないと、運用の現場で都度判断になり、形骸化が進む。
学習除外・監査ログ・IP(組織ポリシーで敷く)
法人プランでは、組織ポリシーとして敷ける統制機能がある。GitHub Copilot は Business / Enterprise で顧客コードをモデル学習に使わない(契約で禁止)うえ、content exclusion で機微ファイルをインライン提案・文脈・Chat・コードレビューの対象から外せる(出典: docs.github.com/参照2026-06-23時点)。
Cursor は Teams で組織横断の Privacy Mode 強制を提供する(コードがモデルプロバイダに保存・学習されない保証=公式の公称であり独立検証値ではない)。Claude Code は Team / Enterprise が Commercial Terms 下で顧客コンテンツを学習に使わず、個人プラン(Consumer Terms)とは別の法的枠組みになる(出典: cursor.com・anthropic.com/参照2026-06-23時点)。なお GitHub Copilot の IP補償は「重複検出フィルタ有効+無変更の提案が対象」という条件付きで、条件を省いて理解しないことが大切だ。
効果測定:DORA/SPACE をAIコーディングに当てる
「導入したが効果が説明できない」を解くのが効果測定である。デリバリーと開発者体験を分けて測る。順に見ていく。
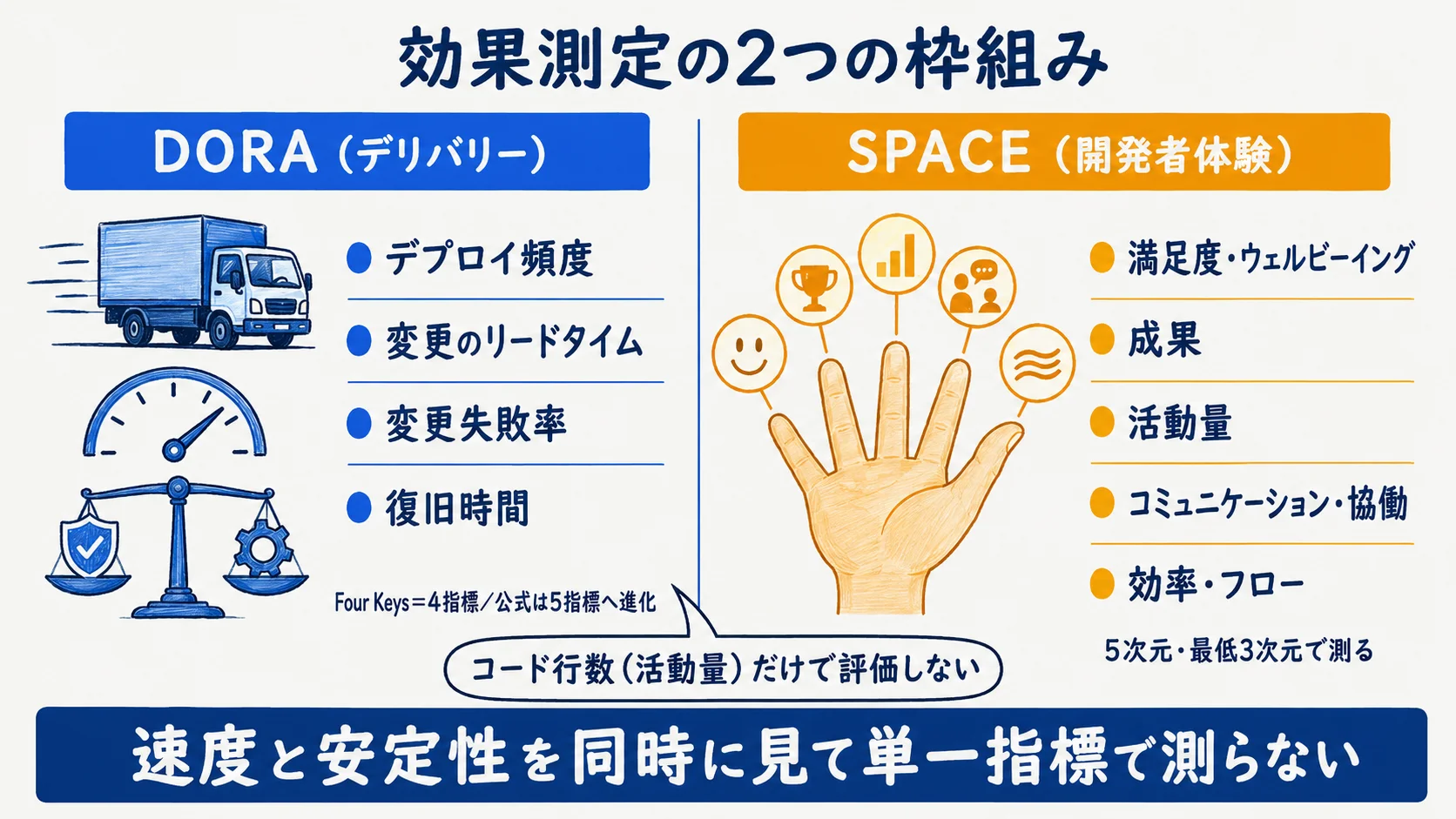
DORA(4→5指標)でデリバリーを測る
DORA(Google/DevOps Research and Assessment)は、広く知られる Four Keys=デプロイ頻度・変更のリードタイム・変更失敗率・復旧時間(MTTR)でデリバリーを測る枠組みだ(出典: dora.dev/参照2026-06-23時点)。公式 dora.dev は現在5指標モデルへ進化しており、rework rate の追加や呼称の更新がある点も押さえておきたい(出典: dora.dev/参照2026-06-23時点)。
AIコーディング導入の効果は「速度2軸(頻度・リードタイム)と安定性(失敗率・復旧)を同時に見る」のが要点だ。速度だけ上げて失敗率が悪化していないかを測る。改善の度合いは現場やツールで大きく異なるため、本記事では一般に紹介される試算の例にとどめ、特定の改善率は断定しない。
SPACE(5次元)で開発者体験を測る
SPACE(ACM Queue 2021・Forsgren 他)は、開発者体験を5次元で捉える。S=満足度・ウェルビーイング、P=成果、A=活動量、C=コミュニケーション・協働、E=効率・フローである(出典: microsoft.com/参照2026-06-23時点)。単一指標で生産性は測れず、最低3次元で測るのが原則だ。
AIコーディングでありがちな失敗は「コード行数(A=活動量)だけで評価する」ことだ。行数が増えても満足度や手戻りが悪化していれば導入は成功とは言えない。DORA(デリバリー)と SPACE(体験)を併用し、片方の改善が他方を犠牲にしていないかを見る。下表が併用設計の骨格である。
| 観点 | フレームワーク | 指標(例) | AIコーディング導入で見るポイント |
|---|---|---|---|
| デリバリー速度 | DORA | デプロイ頻度・変更のリードタイム | 速度が上がっても安定性を犠牲にしていないか |
| デリバリー安定性 | DORA | 変更失敗率・復旧時間(公式は5指標へ進化) | 速度向上と引き換えに失敗・手戻りが増えていないか |
| 開発者体験 | SPACE | 満足度・効率/フロー・協働(5次元・最低3次元) | コード行数(活動量)だけで評価しない |
ツール別の管理機能
法人プランの管理機能を同一軸で並べる。ツール選定(どれが良いか)はせず、「AIコーディングツール比較」に委ねる。当社は Anthropic エコシステムの当事者だが、Claude Code も他ツールと同粒度で並記し、勝者宣言はしない。
| 軸 | GitHub Copilot(Business/Enterprise) | Cursor(Teams/Enterprise) | Claude Code(Team/Enterprise) |
|---|---|---|---|
| 認証・権限 | 組織ポリシー管理(公式記載) | SAML/OIDC SSO・RBAC(Enterpriseで SCIM 追加) | セルフサーブseat管理・Managed policy settings(権限/ファイル/MCP を全ユーザー展開・強制) |
| 学習除外・データ | 顧客コードを学習に使わない(契約)・content exclusion | 組織横断 Privacy Mode 強制(公式公称) | Commercial Terms 下で学習に使わない(個人=Consumer Terms と別枠組み) |
| 監査・コンプライアンス | 監査ログ・IP補償(条件付き) | 使用状況アナリティクス・Admin API・支出上限 | 使用状況アナリティクス・Compliance API・支出上限 |
| 参考価格(確認日2026-06-23・USD・税別) | Business 19/Enterprise 39(/seat・月) | Teams 月払い40(年払い32)/Premium 月払い120(年払い96)(/seat・月・2026-06-01改定後) | プラン体系は公式参照 |
価格・機能は変動が速いため、契約前に各社公式での確認をおすすめする。Cursor の既存顧客は2026-07-01以降の請求サイクルで新価格が反映される(出典: docs.github.com・cursor.com・anthropic.com/参照2026-06-23時点)。
まとめ
AIコーディングエージェントのチーム導入に万能の正解はなく、進め方の設計で決まる。PoC(小さく検証)→ Pilot(限定チームでゲート判定)→ 全社展開(合格条件と撤退基準)の3段階で進め、各段階で権限・レビュー必須化・学習除外のガバナンスを敷き、効果は DORA/SPACE の枠組みで測る。決め手はツールの優劣ではなく「段階判定とガバナンスを最初に設計したか」である。導入の全体像は「AIエージェント導入ガイド」、組織での運用ルールは「生成AIの社内ルール」も参考になる。
自社の開発体制に合う導入の進め方を中立に整理したい方へ
ツール選定から固めたい場合はAIコーディングツール比較(4ツール総合)、導入の全体ロードマップはAIエージェント導入ガイドも参考になります。
よくある質問
- Q. AIコーディングエージェントをチームに導入する進め方は?
- PoC(小さく検証)→ Pilot(限定チームでゲート判定)→ 全社展開(合格条件と撤退基準を明示)の3段階が基本です。各段階で権限・レビュー必須化・学習除外のガバナンスを敷き、効果はDORA/SPACEの枠組みで測ります。
- Q. 個人で使えているのに、なぜチーム導入は難しいの?
- 個人が使えること(習熟)と、チームで安全に・測れる形で回ること(展開)は別の課題だからです。レビューの形骸化・学習除外の漏れ・効果が説明できない、の3点で止まりやすく、ガバナンスと効果測定の設計が必要になります。
- Q. AI生成コードのガバナンスで最初に決めるべきことは?
- リポジトリ権限の最小化、AI生成コードのコードレビュー必須化、学習除外(コンテンツ除外)と監査ログの有効化です。法人プラン(Business/Team/Enterprise)では顧客コードを学習に使わない契約・組織ポリシー強制が利用できます(2026-06-23時点・各公式)。
- Q. AIコーディング導入の効果はどう測ればいい?
- デリバリーはDORA(デプロイ頻度・変更のリードタイム・変更失敗率・復旧時間。公式は現在5指標へ進化)、開発者体験はSPACE(5次元)で測るのが定番です。速度だけでなく安定性も同時に見て、コード行数など単一指標で評価しないことが原則です。
- Q. どのツールを選べばいい?
- 本記事は選定でなく導入の進め方を扱います。ツール選定は規模・既存スタック・ガバナンス要件で分かれるため、4ツールの総合比較記事をご確認ください。法人プランの管理機能(SSO・学習除外・監査)も選定の判断軸になります。
出典・参考資料
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.