AIエージェントのPoCを本番運用に乗せる手順【2026】評価設計・本番化チェックリスト・運用体制
一次ソース検証型AIメディア編集部 ・ 監修: 依田 尚人
目次
デモやPoC(概念実証)ではうまく動いたAIエージェントが、いざ本番に乗せようとすると止まる——「PoCで終わる」のはなぜか。本記事は2026年6月23日時点の公的調査と各社公式情報に基づき、特定ツールを推さず中立に整理する。
PoCが本番に乗らない主因は、技術そのものより「本番前提を逆算したPoC設計・評価ゲート(eval)・可観測性(observability)・ガードレール/人手介入(HITL)・コスト管理」という本番化エンジニアリングが後回しになることにある。本番に乗せる鍵は、PoCの段階でこの4〜5観点を先に決め、評価で移行を判断し、可観測性で運用を回すことだ。
なお当社(YDAIコンサルティング AI編集部)はClaude系ツールのヘビーユーザーであり、Anthropicのエコシステムで開発受託も行う立場にある。そのうえで本記事はどのツール・どのベンダーも勝たせず中立に整理する。失敗そのものの型と診断は「AIエージェントの失敗パターンと診断」へ分岐し、本記事はそれを踏まえて本番に乗せる工程に集中する。
結論:本番化チェックリスト早見
PoCを本番に乗せるとは、技術検証で止めず「信頼性/安全性/運用」の3カテゴリの確認を通すことだ。下表は本番化前に確認する項目を3カテゴリで整理した本記事独自のチェックリストである。
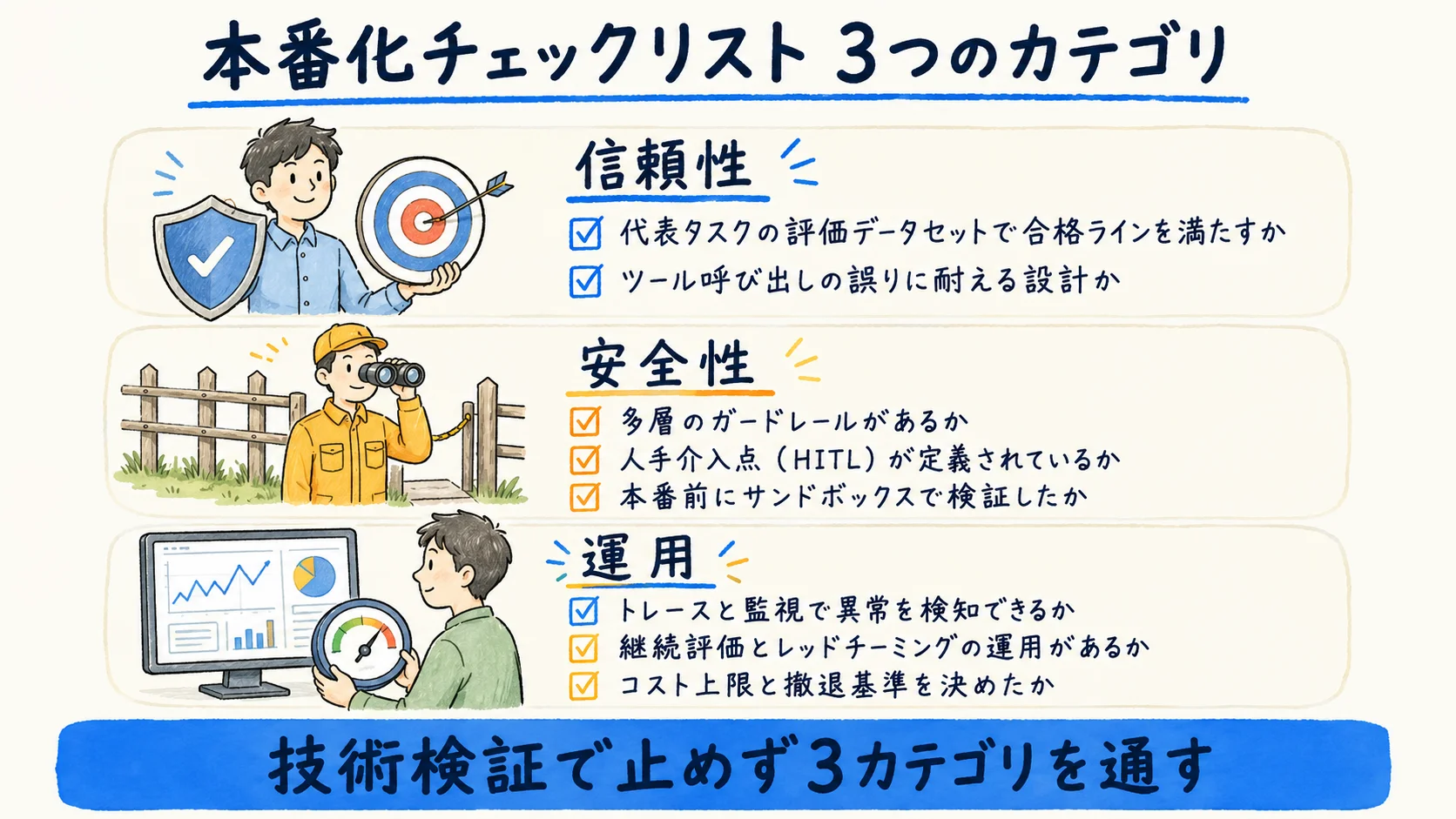
| カテゴリ | 本番化前に確認する項目(例) | 対応する本番化観点 |
|---|---|---|
| 信頼性 | 代表タスクの評価データセットで合格ラインを満たすか・ツール呼び出しの誤りに耐える設計か | 評価(eval)・Golden Dataset |
| 安全性 | 多層のガードレールがあるか・人手介入点(HITL)が定義されているか・本番前にsandbox検証したか | ガードレール・HITL・sandbox検証 |
| 運用 | トレース/監視で異常を検知できるか・継続評価とレッドチーミングの運用があるか・コスト上限と撤退基準を決めたか | 可観測性・コスト管理 |
合格ラインやSLAの具体数値は載せていない。閾値は自社の要件で設定する性質のもので、最新は各公式・自社の要件で確認してほしい。
PoCが本番に乗らない真因
PoCと本番の差は「もう少し精度を上げれば動く」ではなく、本番化エンジニアリングの不在にある。失敗の型と診断は別記事に譲り、ここでは動機づけとして真因を最小限に押さえる。
失敗統計が示す現実
Gartnerは「2027年末までに agentic AI プロジェクトの40%超が中止される」と予測している。理由はコストの増大・ビジネス価値が不明確・リスク管理が不十分の3点だ(Gartnerプレスリリース2025-06-25・将来予測)。
MIT NANDAイニシアチブの報告書「The GenAI Divide: State of AI in Business 2025」は、生成AIパイロットの約95%が測定可能なビジネスリターンを生んでいない一方、成果を出しているのは約5%と報告している(Fortune報道経由・2025)。いずれも年・出典・対象(agentic AI/生成AIパイロット全般)を正確に帰属することが重要で、失敗の型と診断は「失敗パターンと診断」に整理している。
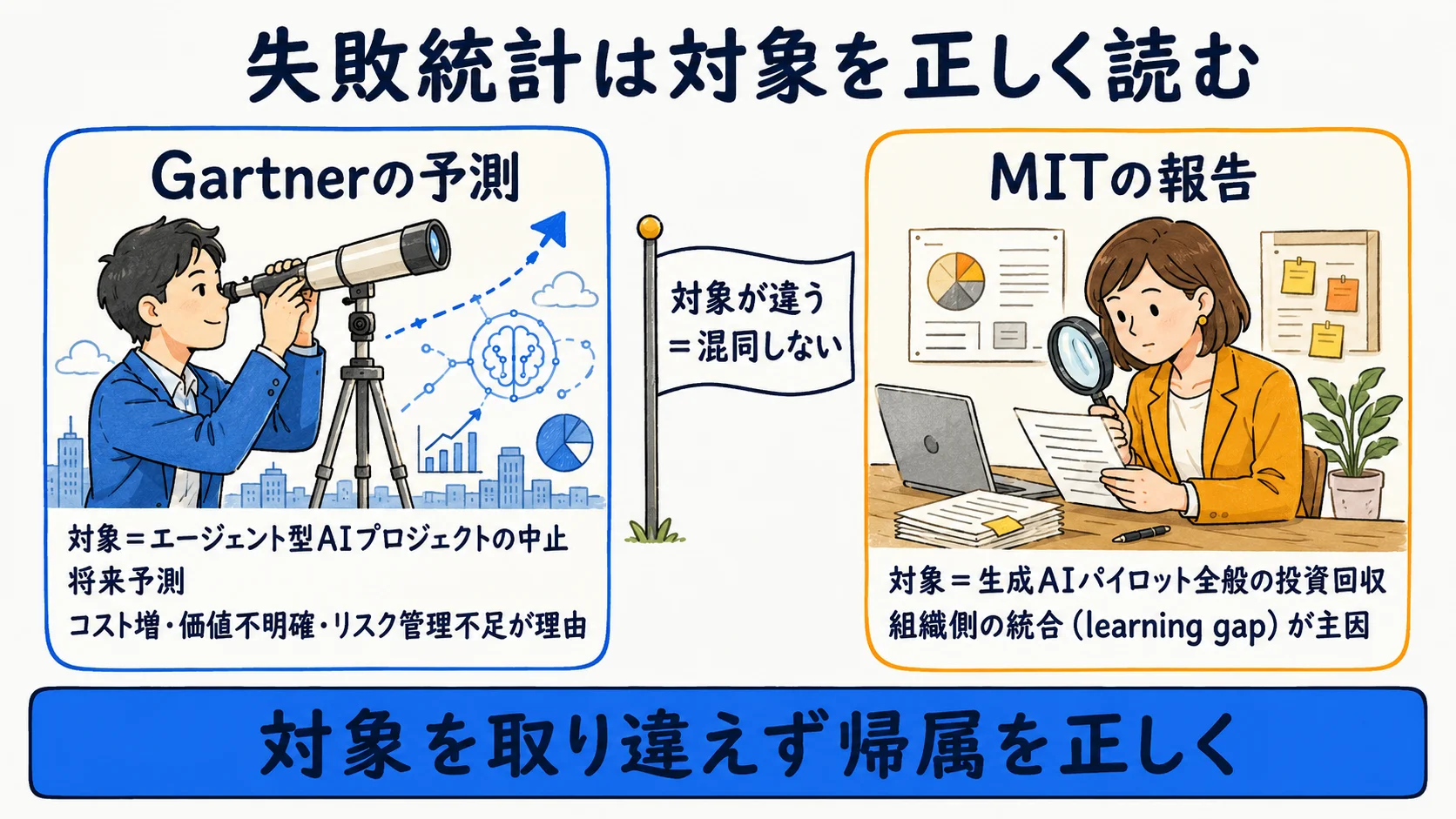
エージェント特有の難所
PoCと本番の差は、出力の非決定性(同じ入力でも結果が揺れる)・ツール呼び出しの連鎖で誤りが伝播する・権限とコストが本番で跳ねる、という固有の難所にある。これらはPoCの小さな試行では表面化しにくい。
MIT NANDAは失敗の主因を技術ではなく組織側の統合(ワークフロー・構造・文化への組み込み=learning gap)とし、専門ベンダーからの購入・パートナーシップ型が内製の約2倍成功すると指摘する(Fortune報道経由)。社内AIで起きやすい落とし穴は「社内AI導入の落とし穴」も参考になる。
ステップ1:PoC設計に本番前提を逆算する
本番化は本番の直前に始めるものではない。PoCの着手時点から本番を逆算して設計するほど、後の移行が滑らかになる。
PoC段階で先に決めておく本番前提
OpenAIとAnthropicの公式は共通して「最も単純な解から始め、成果が明確に改善する場合のみ複雑さを足す(finding the simplest solution possible)」と説く。これを踏まえ、PoC着手時に「対象業務・成功基準・許容できない失敗・人手介入点・撤退基準」を先に言語化しておく。
当社(YDAIコンサルティング AI編集部)の受託・社内AI運用の知見でも、この4〜5項目をPoC段階で先に決めておくと本番化が滑らかになった(数値ではなく定性の経験則として)。導入全体のロードマップは「AIエージェント導入ガイド」に総論として整理している。
評価データセットを最初に用意する
本番化の判断材料は「動いた感」ではなく評価結果だ。PoC段階で代表タスクの評価データセット(期待結果つきの Golden Dataset)を用意し、本番化判断を後で機械的に下せる状態にしておく。
Microsoft Foundryの公式ドキュメントは、pre-production評価で task adherence(タスク遵守)・groundedness(根拠性)・relevance(関連性)・safety(安全性)を測ると整理している(実装観点の参照)。評価軸を先に決めておけば、PoCの結果を本番ゲートにそのまま接続できる。
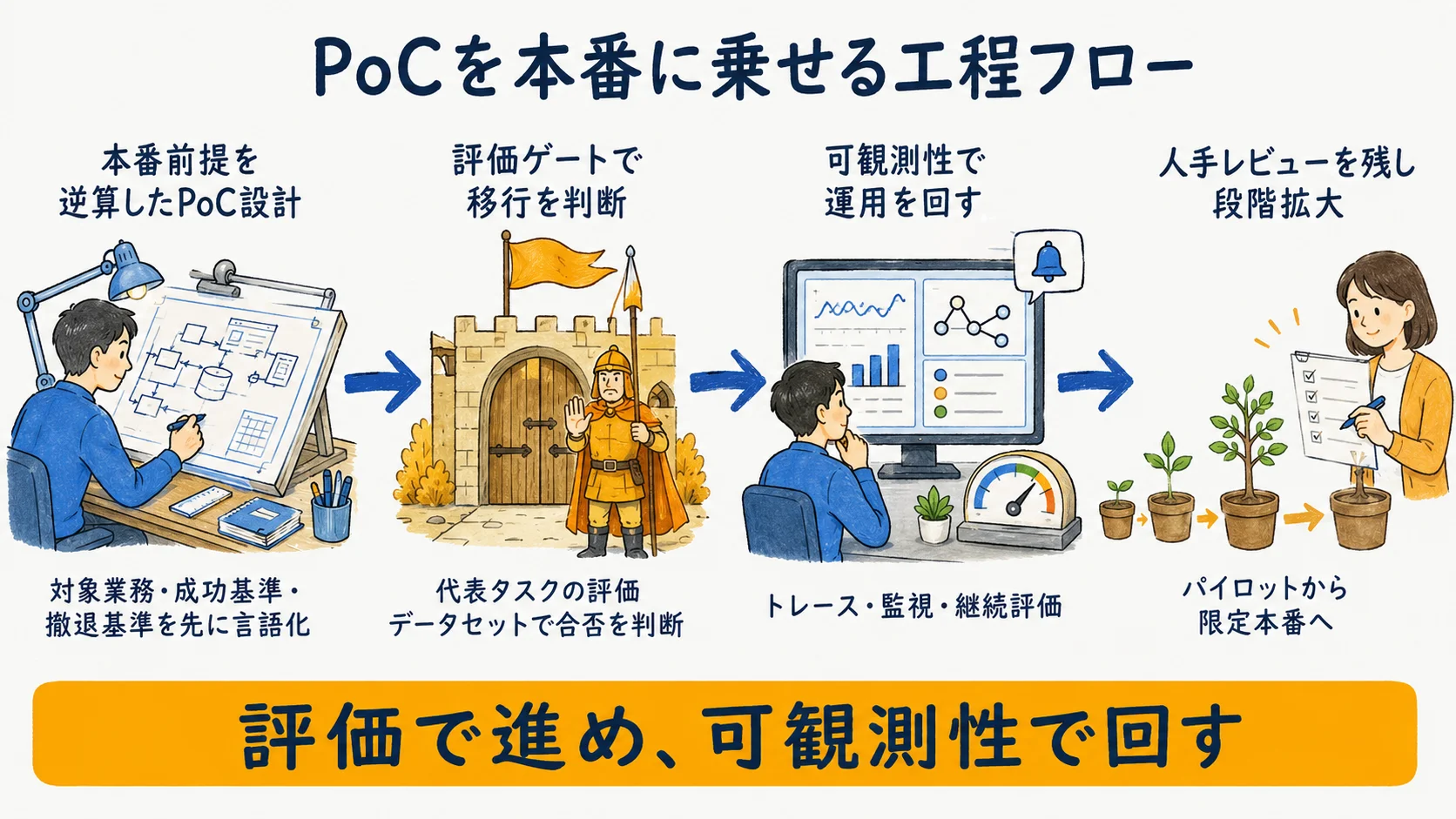
ステップ2:評価ゲートと可観測性
本番化エンジニアリングの核が、移行を判断する評価(eval)と、本番後の運用を支える可観測性(observability)だ。役割が異なるため、混同せず両方を設計する。
評価(eval)=移行を判断するゲート
評価は「PoC→本番に進めてよいか」を判断するゲートである。Microsoft Foundryは評価をAIアプリケーションのライフサイクル3段階(ベースモデル選定→pre-production評価→post-production監視)に統合し、agent固有メトリクスとして tool call accuracy(ツール呼び出し精度)や task completion(タスク完了)を含むと整理している。
LLM-as-judge(別のLLMで出力を採点する手法)や Golden Dataset は概念として広く紹介されるが、合格ラインの数値は本記事では断定しない。合格ラインは「例」として捉え、特定企業の達成値ではなく自社の要件で設定する性質のものだ。
可観測性(observability)=運用の目
本番に乗せた後は可観測性で回す。Microsoft Foundryは可観測性を Evaluation(評価)/Monitoring(監視)/Tracing(トレーシング)の3本柱で定義し、TracingはOpenTelemetry標準ベースだとしている。
さらにpost-production(本番後)では、継続評価(continuous evaluation)・定例レッドチーミング(scheduled red teaming)・品質しきい値アラートを提供すると整理する。eval=移行を判断するゲート、observability=本番運用を監視する目、という役割分担を押さえることが要点だ。

ガードレールとHITL(安全性)
安全性はガードレールと人手介入(HITL)で担保する。OpenAIはガードレールを多層防御(layered defense・LLMベースとルール/正規表現ベース等の組み合わせ)として設計し、human-in-the-loop(人手介入)を含めることを推奨している。
Anthropicは入力のスクリーニングを別モデルで行う方が同一LLMで兼ねるより性能が良いと指摘し、本番投入前にsandboxed環境で十分にテストすることを推奨する。いずれも特定ツールに依存しない安全装置で、中立に取り入れられる考え方だ。
ステップ3:最小構成の運用体制
重厚なAIガバナンス委員会や大規模なMLOps基盤がなくても、本番運用は始められる。中小・中堅向けに現実的な最小構成を示す。
役割分離と三者合意
最小構成は「業務オーナー(何を任せるか)・開発(どう作るか)・監督/レビュー(どこで止めるか)」の三者で、成功基準と撤退基準を合意することだ。MIT NANDAが失敗の主因を組織側の統合と指摘した点を踏まえ、人手レビューを抜かない設計を中立に推奨する。
特定の体制や特定の製品を推すものではない。三者が同じ成功基準・撤退基準を共有していること自体が、本番運用の土台になる。
段階拡大とコスト管理
適用範囲はパイロット→限定本番→拡大、と段階的に広げ、各段で評価ゲートを通す。一度に全社へ広げず、段ごとに信頼性・安全性・コストを確かめながら進めるのが現実的だ。
本番では権限とトークン消費が跳ねやすいため、コスト構造の見積りと上限設計を本番化前に行う。具体的なコスト試算や単価は「AIエージェントの運用コスト」に出所付きで整理しており、本記事では金額を断定しない。
公式が共通して挙げる本番化観点
OpenAI・Anthropic・Microsoft Foundryの3公式が共通して挙げる本番化観点を、1枚に横断統合した。3社を同粒度で並記し、当社のAnthropic当事者性を開示したうえでAnthropic docsを優遇しない。
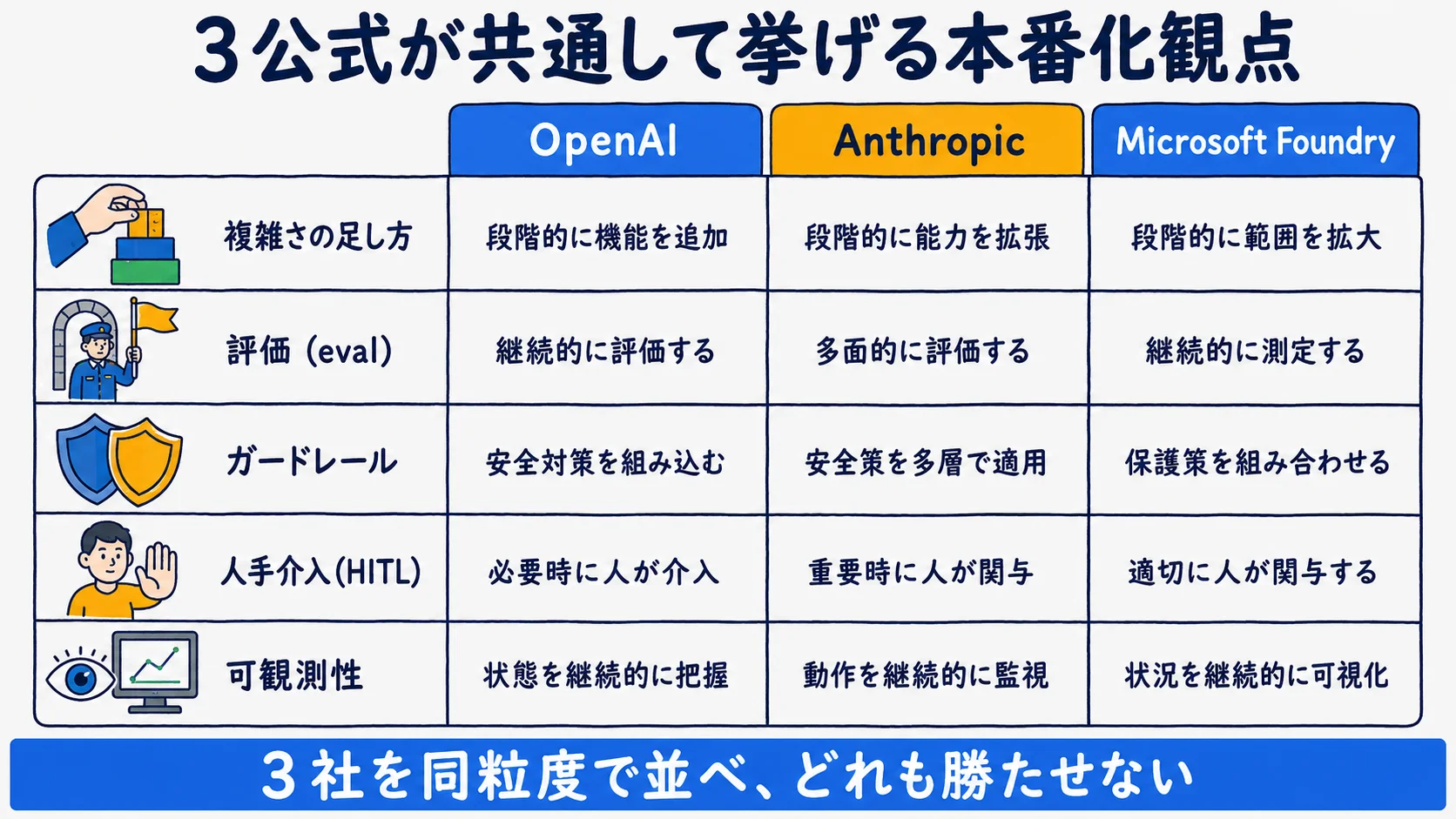
| 本番化観点 | OpenAI(building agents) | Anthropic(effective agents) | Microsoft Foundry(observability) |
|---|---|---|---|
| 複雑さの足し方 | 単一エージェントから始め必要時のみマルチへ | 最も単純な解から始め成果が改善する時のみ複雑化 | ライフサイクル段階で評価を統合 |
| 評価(eval) | 実ユーザーで検証(Start small) | sandbox環境で十分にテスト | pre-production評価で task adherence/groundedness/relevance/safety |
| ガードレール | 多層防御(LLM/ルール/正規表現) | 入力スクリーニングは別モデルが優位 | 安全性メトリクスを評価に含む |
| 人手介入(HITL) | human-in-the-loop を含める | sandbox+適切なガードレール前提 | post-prod監視で品質しきい値アラート |
| 可観測性 | Start small で段階検証 | extensive testing を推奨 | 評価/監視/トレーシングの3本柱・OpenTelemetry |
各観点は3社の公式情報(出典は本記事末尾の出典に集約)から横断抽出した。引用文言は2026-06-23時点のもので、各公式は更新が入りうるため契約・実装前に一次情報で確認してほしい。
まとめ
AIエージェントのPoCを本番に乗せる鍵は、本番前提を逆算したPoC設計・評価ゲート(eval)・可観測性(observability)・ガードレール/人手介入(HITL)・コスト管理という本番化エンジニアリングを、PoCの段階から先に決めることにある。評価で移行を判断し、可観測性で運用を回し、人手レビューを残して段階拡大する——この工程を通せば「PoCで終わる」を避けやすくなる。失敗の型と診断は「AIエージェントの失敗パターン」、導入の全体ロードマップは「AIエージェント導入ガイド」を参照してほしい。
PoCを本番運用に乗せたい方へ
そもそも自社で作るべきか外部サービスを使うべきかから整理したい場合は、AIエージェントの内製と外製(build vs buy)も参考になります。
よくある質問
- Q. AIエージェントのPoCが本番に乗らない原因は?
- 主因は技術そのものより本番化エンジニアリングが後回しになることです。本番前提を逆算したPoC設計・評価ゲート(eval)・可観測性・ガードレール/人手介入・コスト管理を先に決めると本番に乗りやすくなります(2026-06-23時点)。
- Q. PoCを本番に乗せる手順は?
- PoC設計に本番前提を逆算する→評価データセットで移行を判断する(評価ゲート)→可観測性で運用を回す→人手レビューを残しつつ段階的に拡大する、の順です。各段で評価ゲートを通すのが要点になります。
- Q. AIエージェント導入はどれくらい失敗する?
- Gartnerは2027年末までにagentic AIプロジェクトの40%超が中止されると予測しています(コスト増・価値不明確・リスク管理不足が理由)。失敗の型と診断は別記事で解説しています(将来予測・2026-06-23時点)。
- Q. eval(評価)と observability(可観測性)の違いは?
- 評価(eval)は「本番に進めてよいか」を判断する移行ゲート、可観測性(observability)は本番後の運用を監視する目です。Microsoft Foundryは可観測性を評価/監視/トレーシングの3本柱で整理しています。
- Q. 小さな会社でも本番運用できる?
- 重厚なガバナンス基盤は必須ではありません。業務・開発・監督の三者で成功基準と撤退基準を合意し、人手レビューを残してパイロットから段階拡大する最小構成で始められます。閾値は自社要件で設定します(例)。
出典・参考資料
- 1.
- 2.
- 3.
- 4.
- 5.