自律型コーディングAI比較【2026】Devin/OpenHands/SWE-agent/Jules/Codexを中立整理
一次ソース検証型AIメディア編集部 ・ 監修: 依田 尚人
目次
Devin・OpenHands・SWE-agent・Jules・Codex…「タスクを丸投げできる自律型コーディングAI」が増えたが、補助型やフレームワークと混ざって何をどう比べればいいか分かりにくい。本記事が扱う自律型とは、タスクを渡すと非同期やクラウドで自走しPRやdiffを返す出来合いの製品を指す。人が運転席で1操作ずつ書く補助型(Cursor等)は別の型、自分で組む部品(フレームワーク)も別の型として切り離す。本記事は2026年6月23日時点の各社公式・GitHub・arXivに基づき、特定ツールを推さず中立に整理する。
丸投げできる商用クラウド型で素早く始めるなら Devin / Jules / Codex(cloud) が起点、自己ホストでモデル・コスト・データ所在を自分で握りたい・研究やカスタムなら OpenHands / SWE-agent(いずれもMIT・任意のLLMで動く)が起点になる。万能の勝者はなく、自律度が上がるほど人手レビューの監督コストも上がるトレードオフで選ぶ。
なお当社(YDAIコンサルティング AI編集部)は Claude 系ツールのヘビーユーザーであり、Anthropic のエコシステムで開発受託も行う立場にある。そのうえで、OpenHands・Codex・Jules 等が Claude を含む任意のLLMで動く点も中立に併記し、どの製品も勝者にしない。人が運転席で書く補助型の4ツール総合比較は「AIコーディングツール比較(4ツール総合)」、自分で部品から組むなら「AIエージェントフレームワーク比較」を参照してほしい。本記事は出来合いの自律型のみを同じ土俵で横断比較する。
結論:用途別の早見(5製品フル比較表)
万能の勝者はなく、用途で選ぶ。下表は商用×OSSの自律型5製品を「区分・実行環境・到達点・自己ホスト/ライセンス・コスト構造・SWE-benchの立ち位置」の6軸で、各社公式・GitHub・arXivから横断統合した本記事独自の早見表である。
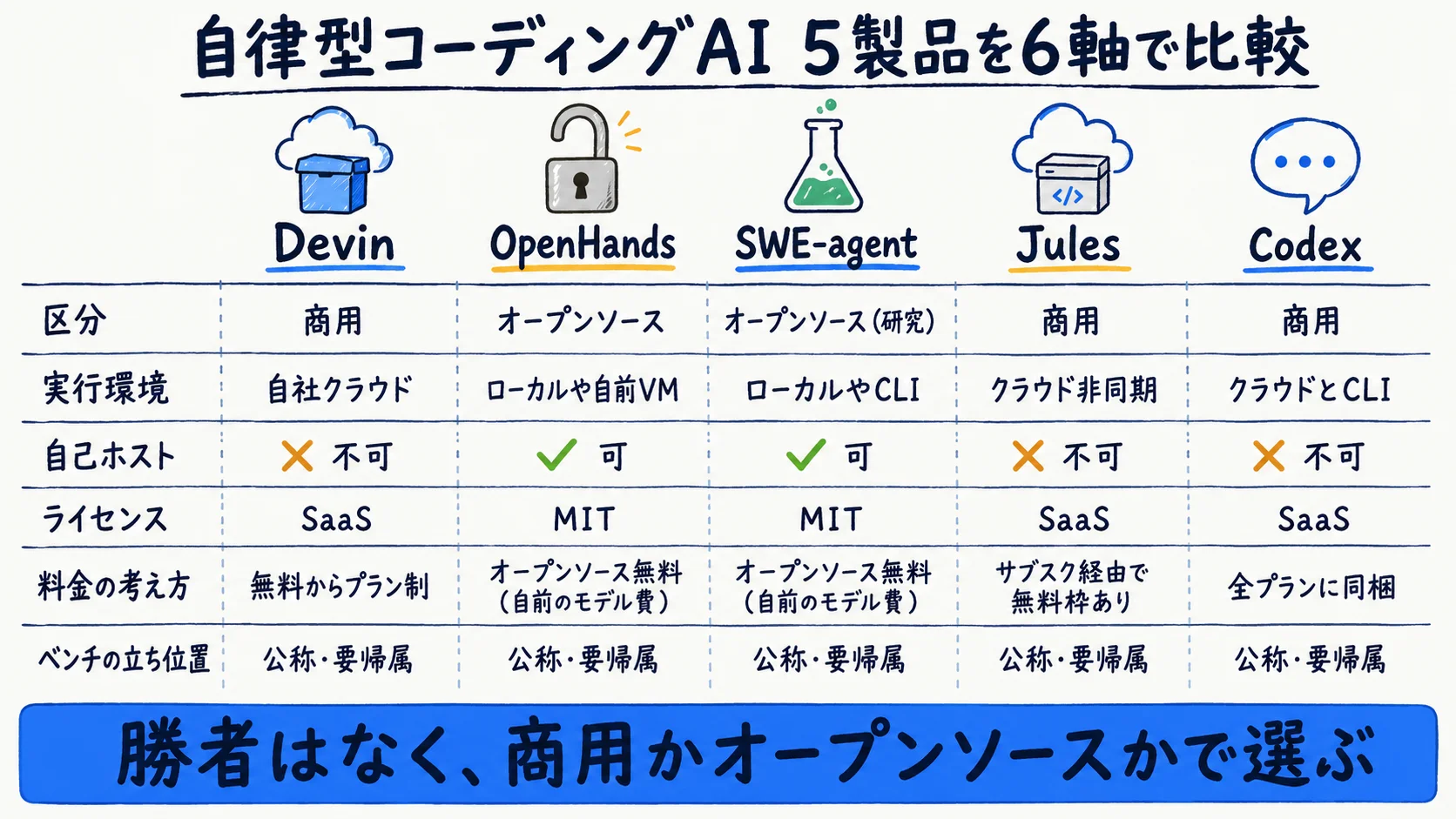
| 軸 | Devin(Cognition) | OpenHands(All Hands AI) | SWE-agent(Princeton主導) | Jules(Google Labs) | Codex(OpenAI) |
|---|---|---|---|---|---|
| 区分 | 商用 | OSS | OSS(研究) | 商用 | 商用 |
| 実行環境 | 自社クラウドVM | ローカル/Docker/自前VM・Cloud | ローカル/CLI | Google Cloud VM(非同期) | クラウド+CLI/IDE |
| 到達点 | PRを返す | PR/diff | パッチ/diff | プラン提示→diff/PR | PR/diff |
| 自己ホスト・ライセンス | 不可(SaaS) | 可・MIT(任意LLM) | 可・MIT(利用者がLLM用意) | 不可(SaaS) | 不可(SaaS・credits) |
| コスト構造(確認日2026-06-23) | Free $0/Pro $20/Max $200/Teams $80+$40seat/Ent.要問合せ | OSS無料(自前LLM費)/Cloudは別 | OSS無料(自前LLM費) | Google AIサブスク経由(無料枠あり) | 全ChatGPTプラン同梱・credits課金 |
| SWE-bench の立ち位置 | 公称(要帰属・ベンチと実運用は別) | SDK公称(モデル/構成依存・要帰属) | 単一Verified値は公式明示なし=定性 | 公称(要帰属) | 公称(要帰属) |
価格・仕様は変動が速いため、本記事の数値は確認日2026-06-23時点である。最新は各社公式(devin.ai・github.com・jules.google・developers.openai.com)で確認してほしい。
自律型コーディングAIとは
自律型とは、タスクを渡すと非同期やクラウドで自走しPRやdiffを返す出来合いの製品を指す。補助型やフレームワークと土俵を分けて初めて、同じ軸で比べられる。
3型の早見(自律/補助/部品)
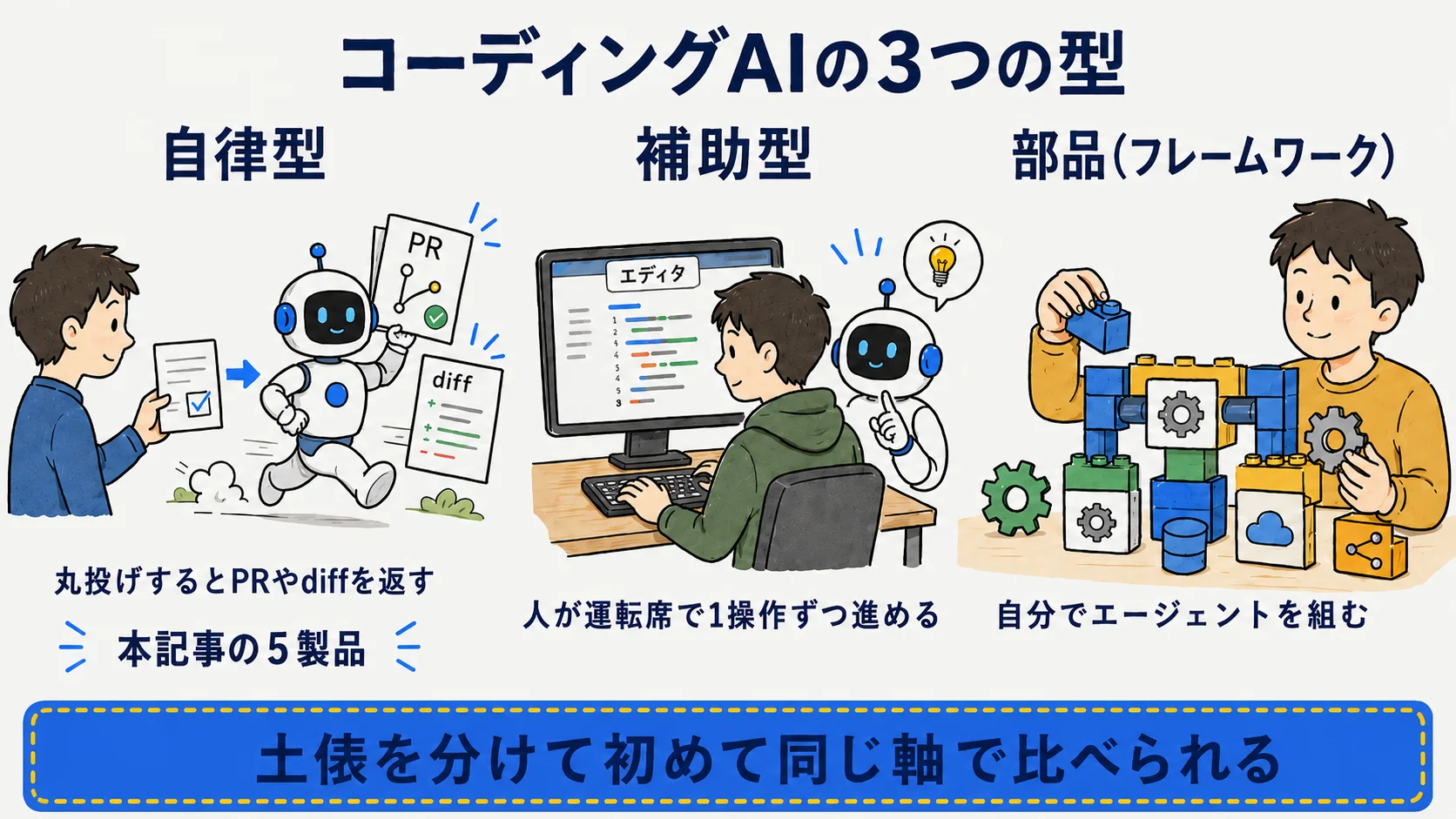
自律型はAIが自走し成果物としてPRやdiffを返す型で、本記事のDevin・OpenHands・SWE-agent・Jules・Codexが該当する。補助型は人間が運転席で1操作ずつ進める型で、エディタ内の変更が成果物になる(→「AIコーディングツール比較」)。部品はフレームワークを使って自分でエージェントを組む型で、自作エージェントが成果物になる(→「AIエージェントフレームワーク比較」)。自律型そのものの定義や仕組みは「AIエージェントとは」も参考になる。本記事は自律型のみを横並べする。
自律度が上がるほど監督コストも上がる
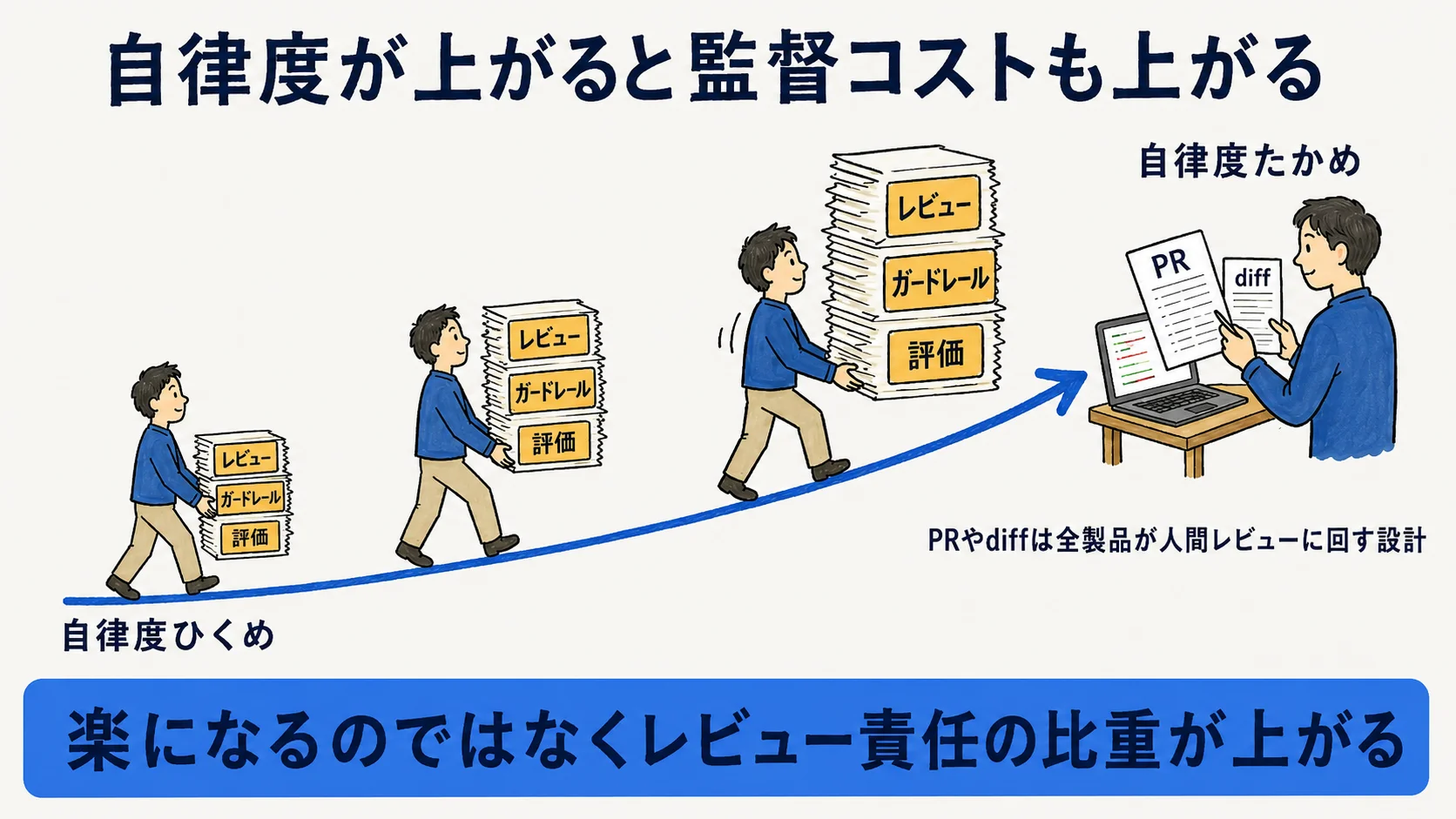
5製品はいずれもPRやdiffを人間のレビューに回す設計で一貫している。つまり丸投げできても、レビュー・ガードレール・評価の手間という監督コストが下流に集中する。自律度が上がるほど「楽になる」のではなく「レビュー責任の比重が上がる」と捉えるのが正確だ。自律型で詰まる典型は「AIエージェント失敗パターン」で整理している。
製品別の整理
ここでは5製品を公平な分量で整理する。数値はいずれも確認日2026-06-23時点で、出典名と対で記す。
Devin(Cognition AI)
Devinは自律型の「AIソフトウェアエンジニア」で、タスクを委譲すると自社クラウド環境で自走しPRを返す(出典: devin.ai/参照2026-06-23時点)。料金は Free $0 / Pro $20 / Max $200 / Teams $80+フル開発シート$40/月 / Enterprise はカスタム(要問い合わせ)である。Enterprise のみ ACU(Agent Compute Unit)課金で、レートは契約のオーダーフォームに従い公開ドル単価はない(出典: docs.devin.ai/参照2026-06-23時点)。なお Windsurf を改名した Devin Desktop はIDE型寄りの製品で、本記事の自律型横断とは土俵が異なるため詳細はここでは扱わない。
OpenHands(All Hands AI)
OpenHandsはOSSの自律ソフトウェアエンジニアリング基盤で、旧称は OpenDevin である(arXiv:2407.16741 で改名が明記されている)。ライセンスはMITで、enterprise/ ディレクトリのみ別ライセンスになる(出典: github.com/OpenHands/参照2026-06-23時点)。ローカル・Docker・自前VMで自己ホストでき、商用の OpenHands Cloud も提供され、任意のLLMと組み合わせて動かせる。Software Agent SDK は SWE-bench Verified 77.6 をプロジェクト公称(バッジから公開スプレッドシートにリンク)としているが、これはモデル・構成・時点に依存する公称値で、独立検証値でもベンチと実運用は別物である(出典: github.com/OpenHands/参照2026-06-23時点)。
SWE-agent(Princeton主導・研究)
SWE-agentはPrinceton大学主導の研究プロジェクトで、NeurIPS 2024 で発表された(出典: github.com/SWE-agent/参照2026-06-23時点)。商用製品ではなく、ライセンスはMIT、利用者が自分でLLMを用意してローカルやCLIで動かす。混同されやすいが、実際のGitHub issueを解くベンチマークの SWE-bench とは別物だ。SWE-agent自体の単一の SWE-bench Verified 値は公式に明示されておらず、軽量版の mini-SWE-agent が SWE-bench Verified で約65%(プロジェクト公称)と案内されている程度のため、本記事の比較表では数値を断定せず「研究プロジェクト・構成依存」と定性表記する。
Jules(Google Labs)
JulesはGoogle Labsの非同期なagenticコーディングエージェントで、リポジトリを安全なGoogle Cloud VMにクローンし背景で作業し、プランを提示してから diff やPRを返す(Gemini基盤)。public beta は2025年5月20日に開始した(早期プレビューは2024年12月)(出典: blog.google/参照2026-06-23時点)。タスク上限は無料が1日15件・3並行、Pro が1日100件・15並行、Ultra が1日300件・60並行で、Google AI のサブスクリプション経由で利用する(出典: jules.google/docs/参照2026-06-23時点)。具体的な月額は Google AI Pro/Ultra の現行プランで確認するのが確実だ。
Codex(OpenAI)
CodexはOpenAIのクラウドエージェントとCLI/IDEで、全ChatGPTプラン(Free $0 / Go $8 / Plus $20 / Pro $100〜 / Business / Enterprise・Edu)に同梱される(出典: developers.openai.com/参照2026-06-23時点)。利用は credits 課金で、百万トークンあたりの入力・キャッシュ入力・出力の単位で計算される。個別のトークンレート値や改定日は本記事執筆時点の一次確認が取れていないため断定せず、最新の単価は公開直前に公式で確認したい。本記事ではCodexを「クラウドでタスクを非同期に委譲する自律文脈」に限定して扱う。
用途別の選び方
順位はつけず、向き不向きで起点を示す。
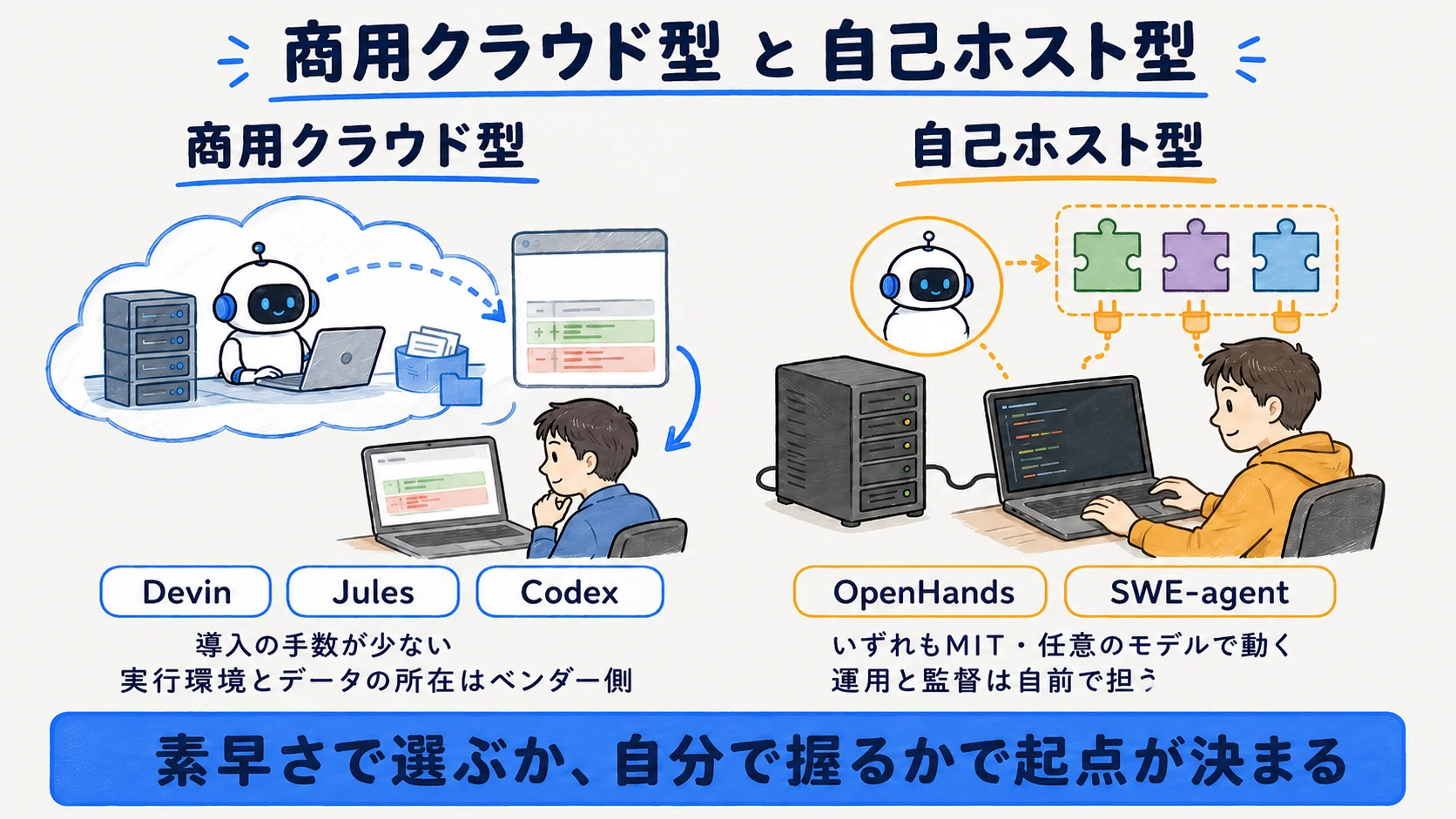
出来合いの商用で素早く丸投げしたい
Devin / Jules / Codex(cloud) が起点になる。ベンダーのクラウドVMで非同期に遂行しPRやdiffを返すため、導入の手数が少ない。一方で実行環境やデータの所在はベンダー側になるため、ログ統制やデータ所在の要件は事前に確認したい。
自己ホスト・コスト/データ統制・カスタムしたい
OpenHands / SWE-agent が起点になる。いずれもMITで任意のLLMと組み合わせ、ローカル・Docker・自前VMで自己ホストできる。研究・内製・コスト統制に向くが、実行環境の運用と監督は自前で担うことになる。自分で部品から組むなら「AIエージェントフレームワーク比較」のほうが適する。
既存サブスク内で小さく試す
Codex は全ChatGPTプランに同梱され無料の $0 から、Jules は無料枠(1日15件・3並行)から、OpenHands と SWE-agent はOSSで自分のLLMキーから試せる。まず手元の環境で相性を確かめ、運用に乗りそうなものを広げるのが堅実だ。
SWE-benchスコアの読み方
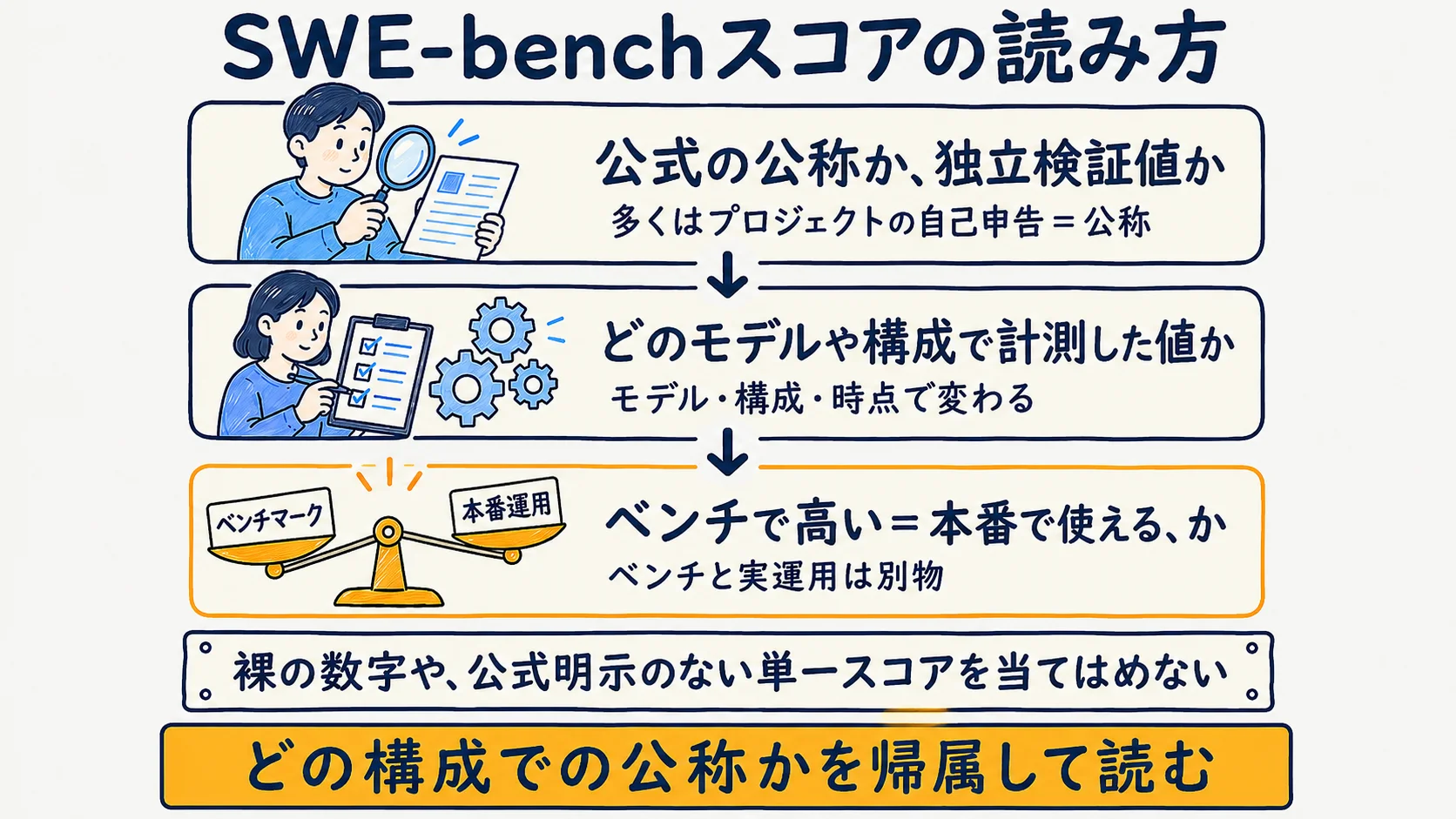
SWE-bench は実際のGitHub issueを解くベンチマーク(Princeton/Stanford・MIT)で、ツールの SWE-agent とは別物である。スコアはモデル・harness構成・時点に依存し、各製品のプロジェクト自己申告(公称)であることが多く独立検証値ではない。「ベンチで高い」は本番運用の信頼性を意味しないため、OpenHands SDK の 77.6 のような値も「どのモデル・構成で計測した公称か」を帰属して読む。裸の数字や、公式明示のない SWE-agent 自体の単一スコアを当てはめる読み方はしない。
まとめ
自律型コーディングAIに万能の勝者はなく、商用クラウド型かOSS自己ホスト型かを軸に、実行環境・ライセンス・料金体系の相性で選ぶ。素早く丸投げしたいなら Devin / Jules / Codex(cloud)、自己ホストでモデルやコストを握りたいなら OpenHands / SWE-agent が起点だ。いずれも自律度が上がるほど人手レビューの監督コストが増える点は共通する。人が運転席で書く補助型は「AIコーディングツール比較」、自分で部品から組むなら「AIエージェントフレームワーク比較」へ。料金や提供形態は変動が速いため、契約前に各社公式での確認をおすすめする。
自社の開発体制に合うツールを中立に整理したい方へ
どのツールが自社に合うかを整理したい場合は、AIエージェントとは何か(仕組み・種類・できること)も参考になります。
よくある質問
- Q. 自律型コーディングAIとは?
- タスクを渡すと非同期やクラウドで自走し、コードを書いてPRやdiffを返す出来合いのAIです。人が1操作ずつ運転する補助型や、自分で組むフレームワークとは別の型で、Devin・OpenHands・SWE-agent・Jules・Codexなどが該当します。
- Q. Devin・OpenHands・SWE-agent・Jules・Codex の違いは?
- 商用クラウド型がDevin・Jules・Codex(cloud)、OSS自己ホスト型がOpenHands(旧OpenDevin・MIT)とSWE-agent(Princeton主導の研究・MIT)です。実行環境・ライセンス・料金体系が主な違いで、用途で選びます(2026-06-23時点)。
- Q. 自律型コーディングAIはどれを選べばいい?
- 万能の勝者はありません。素早く丸投げしたいなら商用クラウド型(Devin/Jules/Codex)、自己ホストでモデルやコストを自分で握りたいならOSS(OpenHands/SWE-agent)が起点です。自律度が上がるほど人手レビューの監督コストも増えます。
- Q. OpenHandsは無料・自己ホストできる?
- はい。OpenHandsはMITライセンスのオープンソースで、ローカルやDocker、自前のVMで自己ホストでき、任意のLLMと組み合わせて動かせます(商用のOpenHands Cloudも別途あります)。旧称はOpenDevinです(2026-06-23時点)。
- Q. SWE-benchのスコアは実力を表す?
- スコアはGitHub issueを解くベンチマークの値で、モデルや構成・時点に依存する公称値です。本番運用の信頼性とは別物で、ベンチで高い数値が実務で使えることを意味しません。掲載値はどの構成での公称かを確認して読みます。
出典・参考資料
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.